AI and Ruby on Rails
- Artificial Intelligence
- Ruby on Rails
- Tutorial

Phil Calçado
Ruby on Rails revolutionized web development by making the complex simple through convention over configuration. This approach brought us household names like Shopify, SoundCloud, and Instacart - all built by small teams that could focus on their product instead of infrastructure.
Rails developers are known for going from idea to production in record time, but building AI-powered products brings back all the complexity Rails worked so hard to eliminate. Instead of focusing on their product, developers become AI experts just to ship straightforward features!
Just as Rails made web development accessible through convention over configuration, Outropy is doing the same for AI. Ruby developers have always been able to use Outropy’s APIs, but today we’re excited to announce native Rails integration that brings the framework’s developer experience to AI!
To mark Outropy’s arrival in the Rails ecosystem, we’ve prepared this comprehensive guide, where we’ll share practical patterns and hard-won lessons from building AI-enabled web applications at scale. We’ll examine common pitfalls and their solutions through the lens of a real open-source product, showing how to evolve from basic AI features to production-ready implementations. While we’ll use Outropy’s Rails integration in our examples, the engineering principles we’ll explore apply regardless of your AI stack.
Jump to the tutorial if you want to dive straight into the code for outropy-rails.
Our Case Study: Evolving Campsite’s AI Features
Outropy was originally a productivity tool for engineers, so we naturally geek out in this space. Among companies doing remarkable work here, Campsite stood out by building an incredible tool that aggregated project activity with unbeatable UX. While the team joined Notion, they left a fantastic parting gift: their entire application as open source!
The Campsite repository provides an excellent example of a real-world Rails application, and we are going to use it as our case study in this article. The Campsite Github has everything you need to run the app, but we’ve also created a fork that includes the Outropy integration code and seed data we’ll use in this guide.
Campsite’s AI Assistant
Six months ago, Campsite added AI-powered call transcription and summarization to its platform. While standalone services like Fireflies.ai have made meeting summaries commonplace, integrating AI directly into a collaboration platform unlocks far more powerful possibilities. When your AI assistant has context about your projects, teams, and workflows, it can do much more than generate meeting notes – it can connect insights across conversations, update project status, identify action items, and keep everyone in sync automatically.
Campsite had started exploring this potential with their integrated call features. Here’s how Campsite founder Brian Lovin described it:
Okay, we're shipping a lot of call improvements on Campsite this week...they're becoming really, really powerful.
— Brian Lovin (@brian_lovin) July 16, 2024
To start: you can now host + record calls with external participants!
All of my onboarding calls happen on Campsite: I record them, Campsite's AI summarizes the… https://t.co/r3OIzsuhJJ
Here’s how their initial implementation looks in action:
This initial implementation, while a great first step, faces common challenges we see in early AI adoptions. Here are three that we are going to tackle in this article:
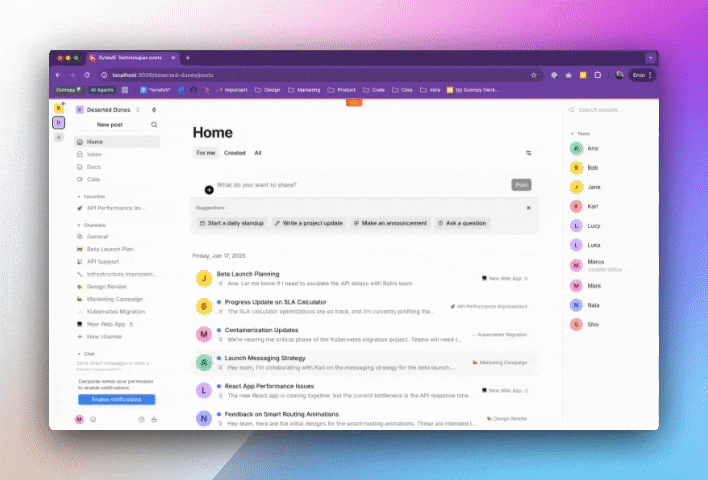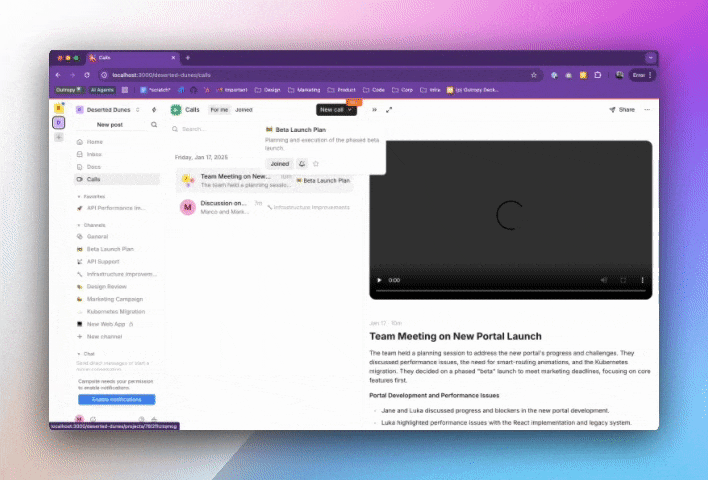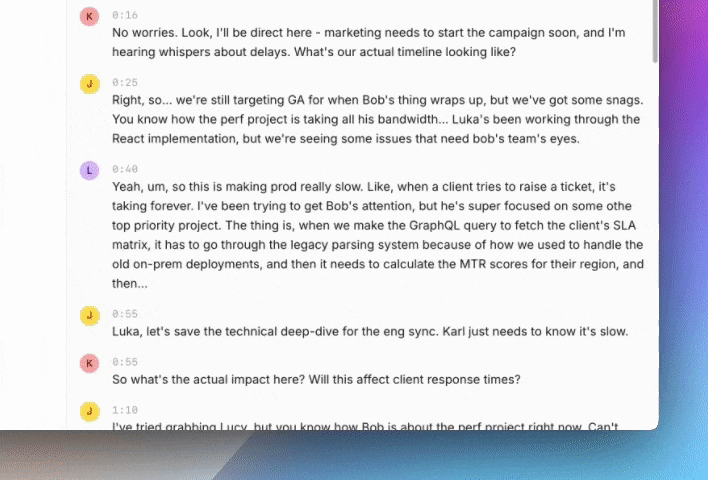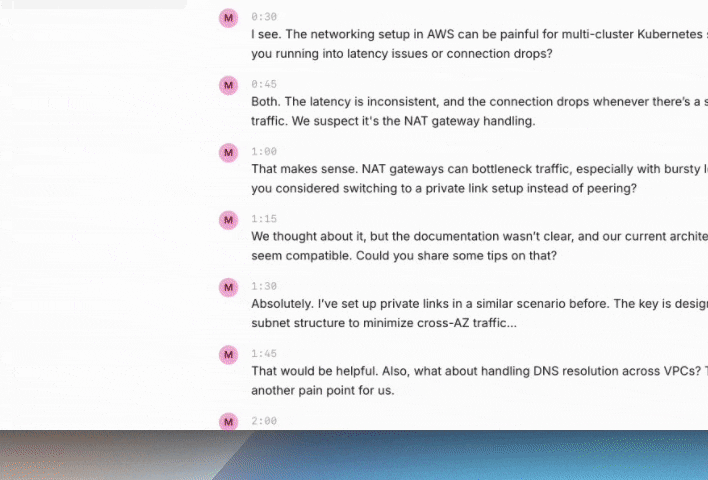
- Summaries are Court Transcripts: Reading “Alice discussed databases, then Bob mentioned deployment, then Charlie suggested a timeline” forces you to mentally reconstruct what happened - a critical scaling issue forced a launch delay. The AI shortens the transcript but doesn’t actually summarize the story.
- Guessing Context Without a Company Badge: When someone says “Project Aurora needs more auth work,” the AI has encyclopedic knowledge about authentication but doesn’t know Aurora is your payment system rewrite. Like a brilliant consultant who’s never worked at your company, it can only make educated guesses about what things mean.
- Filling in Blanks with Plausible Fiction: Instead of admitting uncertainty, the AI invents plausible-sounding details to bridge its knowledge gaps. For example, when it hears “Sarah’s API concerns,” it might craft a compelling story about API security, even though Sarah was discussing performance. These subtle, reasonable-sounding hallucinations are far more dangerous than obvious mistakes.
These challenges aren’t unique to Campsite but rather typical growing pains when teams first deploy AI features in production. While early prototypes often show amazing results, teams quickly discover that truly helpful AI needs to rely less on general knowledge and more on your organization’s specific context. That’s where techniques like Retrieval Augmented Generation (RAG) come in, but before we dive into improvements, let’s look at how it’s currently implemented.
How Campsite Built Its AI Summaries
Campsite’s implementation follows Rails conventions elegantly, making it easy to understand if you’re familiar with the framework. Let’s walk through how it works.
The Data Model
At its core, the feature revolves around two key models: Call and CallRecording. While there’s more to them, they follow typical Rails patterns:
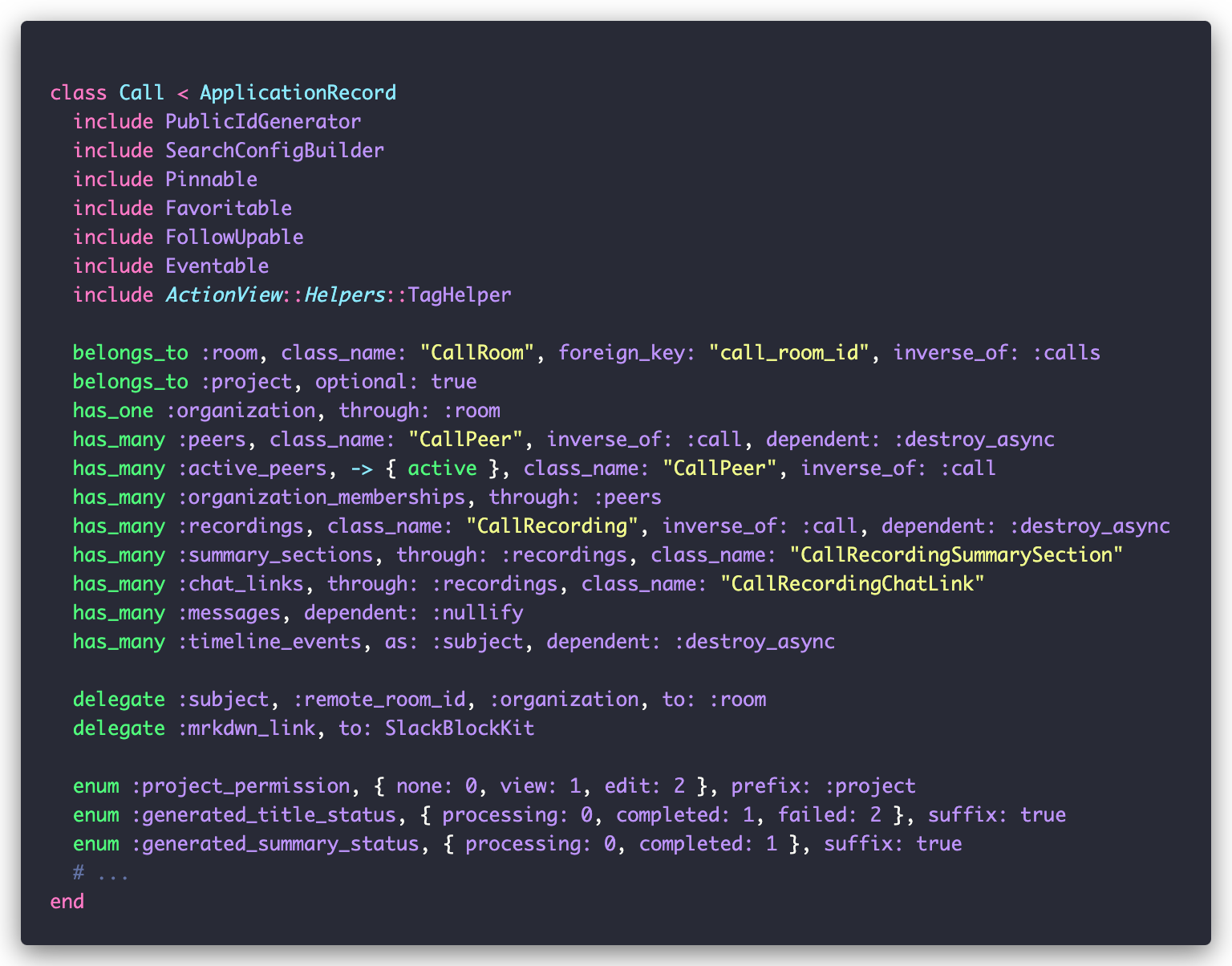
The Video Call Flow
Campsite uses 100ms (great name) for video conferencing, which also provides call transcripts in WEBVTT format (example here). When a call ends, 100ms makes a callback to Campsite’s EventsController, triggering a series of background jobs. While the README explains the full setup, you can test this flow by manually triggering these callbacks from the Rails console.
Generating Summaries
The main job is GenerateCallRecordingSummarySectionJob, and it looks like this:
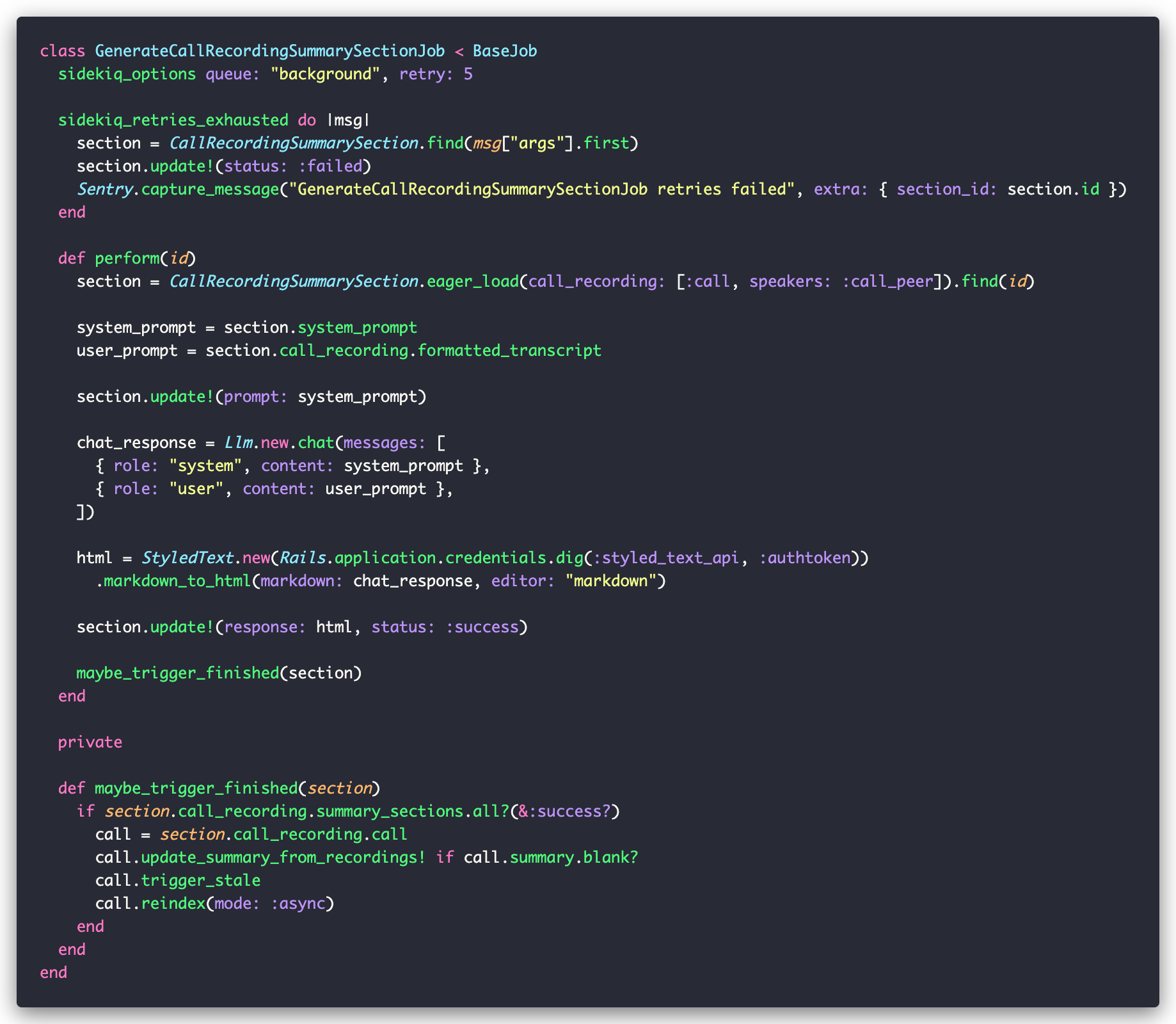
This job works with the CallRecordingSummarySection model, which departs from the usual conventions:
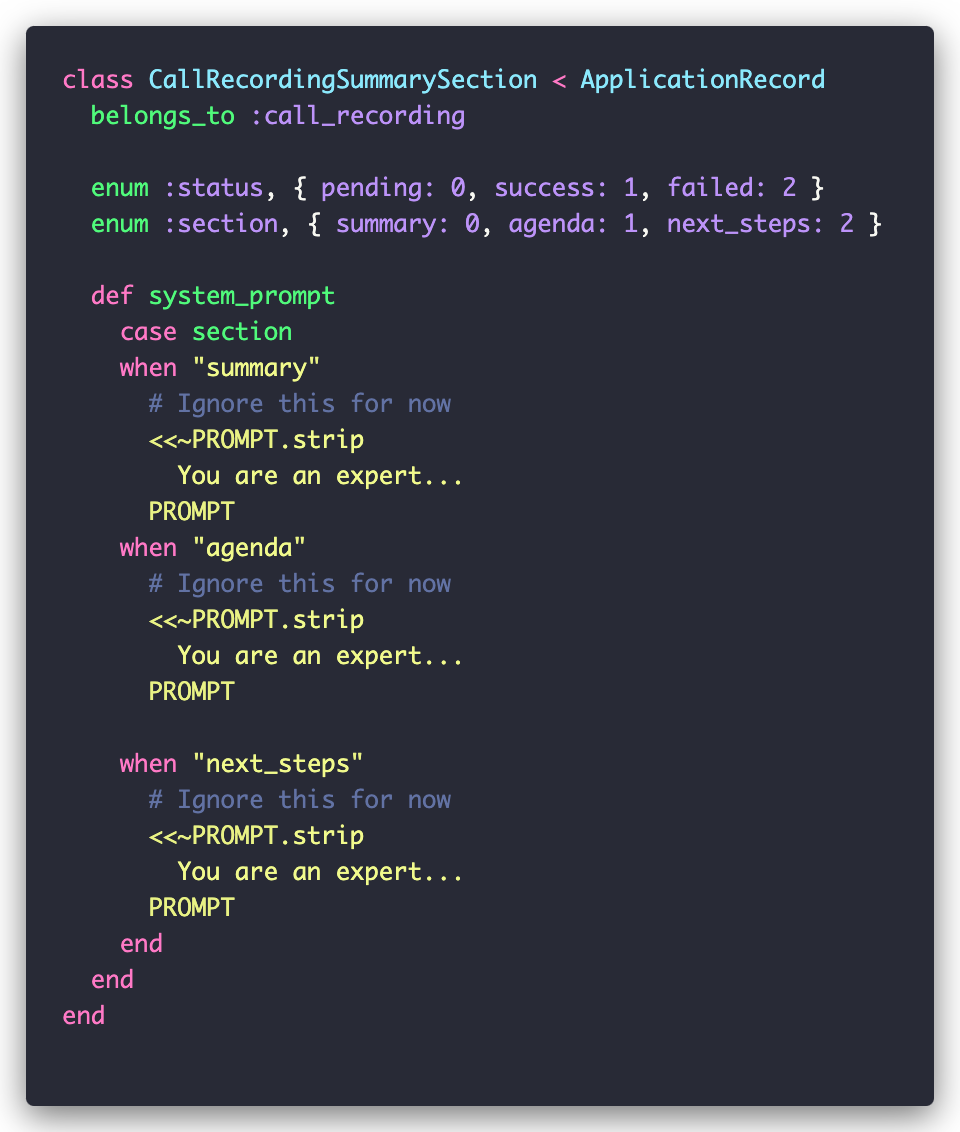
The job creates three CallRecordingSummarySection instances for each call: summary, agenda, and next_steps. For each section, it fetches the appropriate prompt and sends it with the call transcript to GPT-4 via a wrapper around OpenAI’s SDK. The response and prompt are saved in the corresponding record:
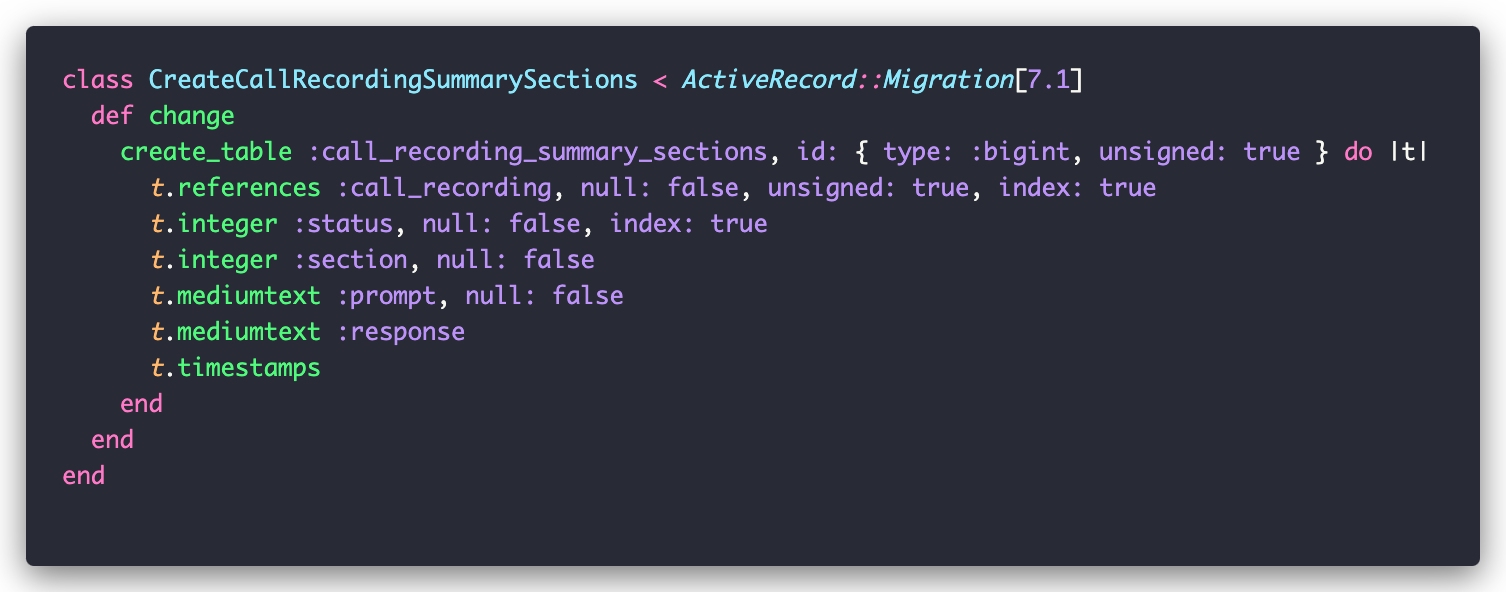
Finally, the CallRecording model can generate the HTML text we see on the screen:
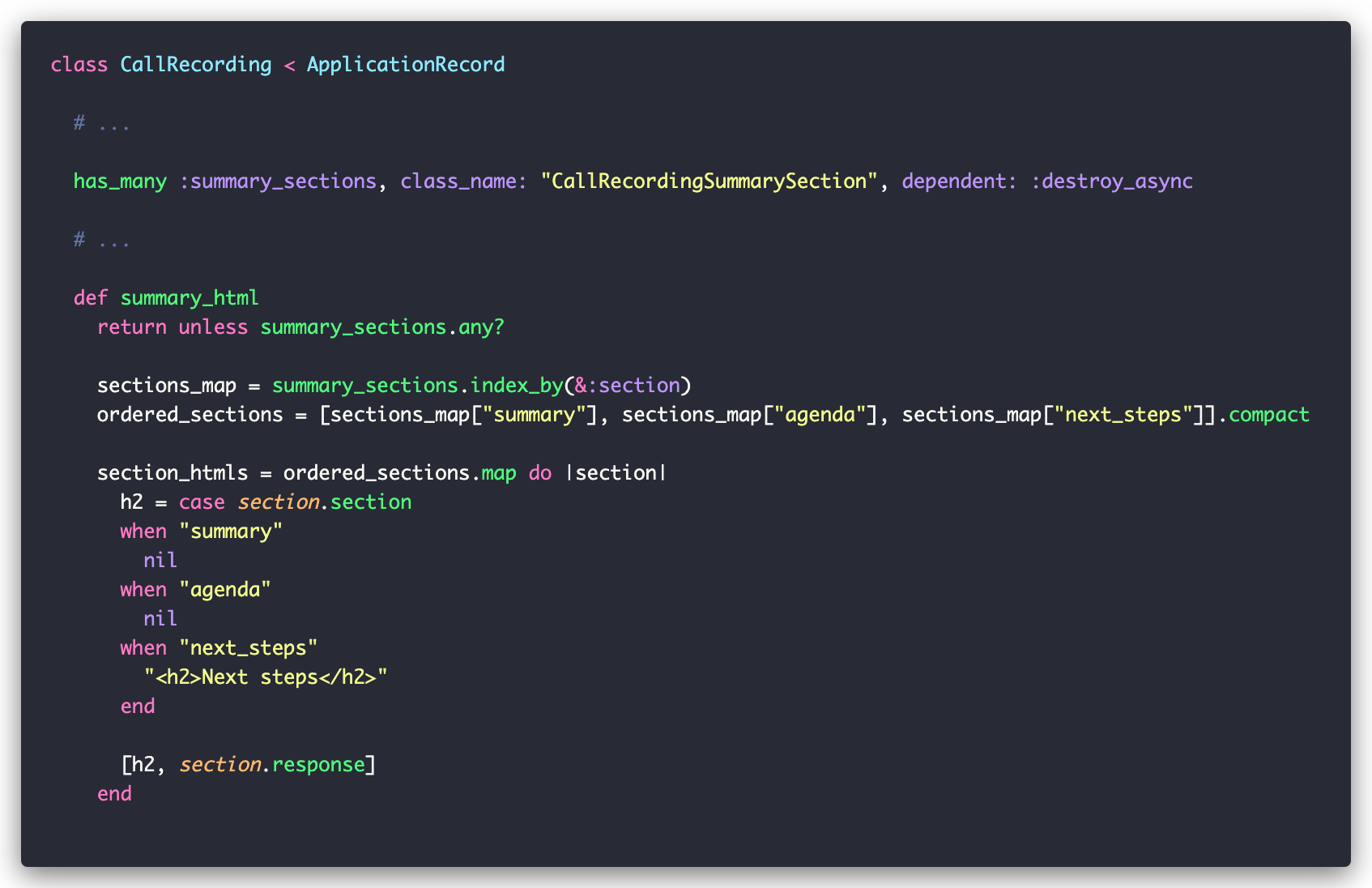
While Campsite uses AI in other places, they all follow simpler versions of this pattern. It’s a clean implementation that follows Rails conventions while keeping AI-specific logic well-organized.
Learning from Campsite’s AI Implementation
While simple, Campsite’s implementation demonstrates several key patterns we’ve learned are crucial for production AI systems. Let’s examine three of them:
Break Features into Smaller Parts
The most important lesson in building AI systems is that they’re just like any other software - they work best when broken down into focused components that work together.
Campsite does this well with its summary generation. Instead of using a single massive prompt, they split summary into three distinct parts:
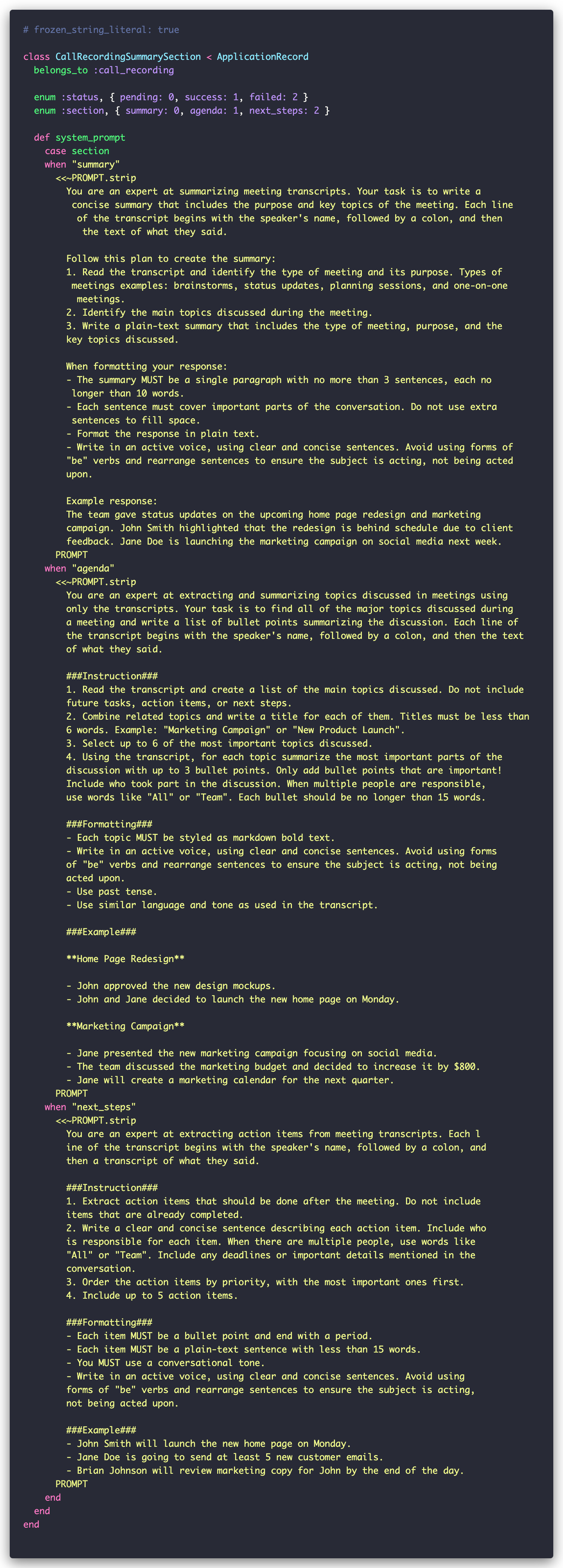
In our experience, this separation not only yields better results but enables reuse—those action items could easily feed into Jira or Linear backlogs.
At Outropy, we’ve found that breaking down complex AI features into smaller, focused tasks is so fundamental to building reliable AI systems that we made it central to our platform. When building with Outropy, you use tasks like summarize, classify, or extract, which are composed to build sophisticated features:
Save Everything: Prompts, Inputs, Parameters…
Developing AI features is an exercise in trial and error, where small prompt tweaks can lead to unpredictable results and vendors constantly update their models and middleware. This makes it critical for production apps to log every prompt, model version, and parameter along with the responses. Without this data, you can’t effectively debug issues, track vendor update impacts, or safely evaluate changes.
Campsite does a good job saving the prompts used to generate each response. However, they could go further by logging model versions and parameters like temperature and seed. This becomes especially important as you move from simple LLM calls to more sophisticated pipelines that combine multiple AI components.
That’s why Outropy saves every parameter, input, and output from each task. Beyond just making this data available through our API and UI for your own analysis, we use it to optimize your tasks - automatically selecting the most efficient components and configuring them with the best parameters.
Embrace Asynchronous Processing
AI operations introduce new scalability challenges to web applications. While most apps can defer thinking about async patterns until they hit significant scale, the high and unpredictable latency of AI models forces you to handle asynchronous processing from day one. Even simple features need to manage long-running operations and handle cases where users are actively waiting for results.
Campsite handles this well using Rails’ built-in async capabilities through background jobs and callbacks. Their approach works great for processing call recordings, where users don’t expect immediate results. However, they would face new challenges if they needed to provide real-time AI features where users are actively waiting for responses.
At Outropy, we’ve built patterns for handling both async and sync scenarios into our platform. Beyond the basics of background processing, we provide smart caching based on semantic understanding of inputs via feature extraction, automatic request batching, and streaming responses. This means you can focus on building features while we handle the complexity of scaling AI operations.
Improving Campsite’s AI Implementation
As someone who has spent much time thinking about AI and productivity tools, we have a long wishlist for what we think Campsite could do to improve their AI-powered experience.
To keep things practical, let’s focus on three major areas that are common to all AI applications, not only productivity or even summarizing:
Play-by-play Summaries Suck
One of the most interesting ironies of Generative AI is that while content summarization is usually the first AI feature people add, most of these summaries suck. LLMs are great at explaining tough concepts simply, so why do they struggle with basic business meetings?
The issue is that even though an LLM might contain the contents of every business book, guidance is needed to determine which of these (often conflicting) playbooks better applies to each situation. Without this guidance, the AI ends up shortening content instead of truly summarizing it. Take daily standups: some experts recommend the “yesterday/today/blockers” format, while others focus on identifying bottlenecks to achieve flow state. The LLM knows both approaches but doesn’t know which one your users prefer.
The solution is to provide specific guidelines for different types of meetings and audiences. Stakeholder updates should focus on reactions and concerns, while project reviews should highlight changes since last time. Different audiences need different perspectives too - engineers want technical details, managers need strategic insights, and external teams need higher-level context.
This is where our approach of breaking a problem into smaller tasks comes in. First, classify the meeting to understand its type and purpose. Each type gets its own guidelines, and another task can learn patterns from your organization’s meetings to identify new types. Finally, contextualize the content for different audiences - either on the fly or by proactively generating summaries for key personas like engineers, external teams, and managers.”
Hallucinations caused by lack of context
LLMs can generate false information in different ways. The most obvious are pure hallucinations—completely made-up content that bears no relation to reality. While these can be problematic, they’re relatively easy to catch with good guardrails that verify if the output matches the input context. Modern LLMs like GPT-4 rarely produce these obvious hallucinations.
The more insidious problem comes from LLMs’ tendency to fill in gaps in their context with plausible but incorrect information. These models are trained to provide complete, coherent responses, so when faced with partial information, they’ll make assumptions to bridge the gaps. While “Then the elephant raised their hand and sang a sad song” is obviously false, “Bob gave updates on the Q4 numbers” sounds perfectly reasonable - unless you know Bob left the company two weeks ago.
The solution is to provide LLMs with complete, relevant context. In Campsite’s case, this means giving the model access to not just the meeting transcript, but also project staffing and statuses, backlogs, and organizational structure at the time of the meeting. When the model knows Bob left and Sarah took over the Q4 reporting, it has no need to make assumptions or fill in gaps with potentially incorrect information.
The first challenge is finding out the relevant information and slicing and dicing them in a way that not only fits an LLM’s context window but also doesn’t cause more confusion. This is one of the biggest challenges when building RAG pipelines, and there are many different techniques that can help but they are heavily dependent on the type and shape of data and expected result.
But even if you have perfect querying of your data, pulling live information while generating summaries can lead to inconsistencies. Our approach uses an explain task first to create a document that captures all relevant context at the time of the meeting. Then, use this frozen snapshot as input to contextualize your summaries. This produces better results because each task has a clear focus - explain handles understanding the meeting’s context, while contextualize can focus purely on crafting the right summary for each audience.
Making AI Part of Your Domain Model
Most teams treat LLMs as presentation-layer components, using them primarily to display information in different formats. This vastly undersells their potential as reasoning engines that can understand and transform your business data.
Consider how systems of record like Jira or even Campsite itself struggle to stay current. A five-minute conversation can render them outdated - tasks get cancelled, priorities shift, new projects emerge. Traditional systems wait for someone to update this information manually, which often doesn’t happen in a timely fashion.
”The solution is to treat AI-processed meeting transcripts as legitimate inputs to your system of record, just like user clicks or form submissions. When Campsite understands meetings in a structured way, it can automatically update or create database records. A conversation about moving a deadline becomes a data point that updates project timelines; a mention of blocking issues creates new tasks automatically.
The challenge is that LLMs with structured outputs, like OpenAI’s function calls, behave more like ETL pipelines than application code. Mapping between business logic and AI concepts like tokens and prompts creates unnecessary friction. This is why Outropy tasks work directly with your models, as inputs, outputs, and reference data. Much like how ActiveRecord bridges objects and databases, Outropy handles the translation between your domain models and AI operations under the hood.
Rebuilding Campsite’s AI with Outropy
Tasks: Building Blocks for AI Features
Let’s look at how to rebuild Campsite’s features while maintaining Rails’ elegance and simplicity, using Outropy’s main abstraction: Tasks. You can think of Tasks as smart microservices that you create by calling an API. You define what you want to accomplish and Outropy builds and maintains the pipeline, handling all the AI complexity for you.
When building AI features like Campsite’s meeting summaries, you’ll find yourself doing similar operations over and over - categorizing content, extracting specific information, making decisions based on complex data. Tasks map directly to these common operations. In our beta, we provide task types for all these common needs:
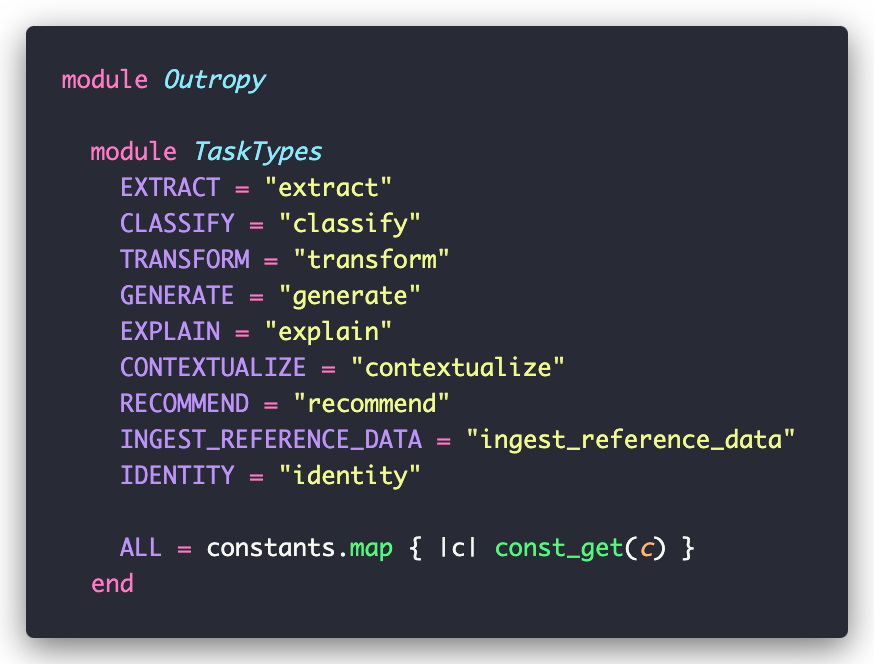
Creating a Task is straightforward. You provide a name, choose one of the types above, and specify what kind of input and output you want - you can use any Ruby object, including ActiveRecord models.
Tasks can also access reference data—whether that’s databases, documents, APIs, or even ActiveRecord models. This reference data helps the Task understand your application’s context when processing inputs.
Finally, you can provide guidelines or instructions that tell the Task how to handle your specific use case. These guidelines are like documentation for the AI - they help it understand your application’s domain and requirements.
Here is how it looks like:

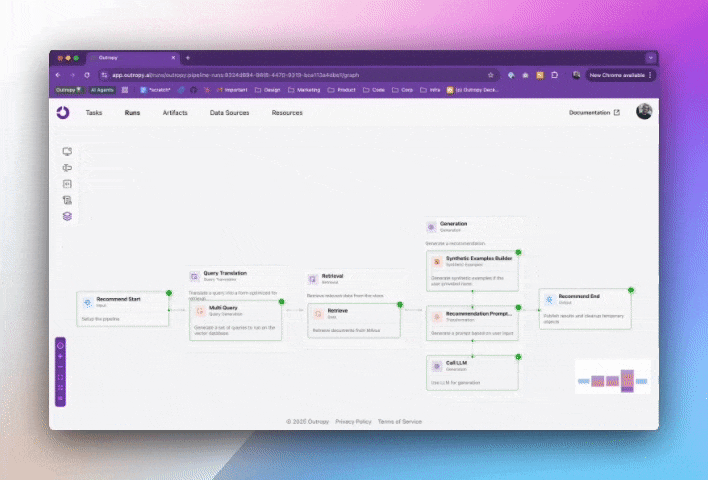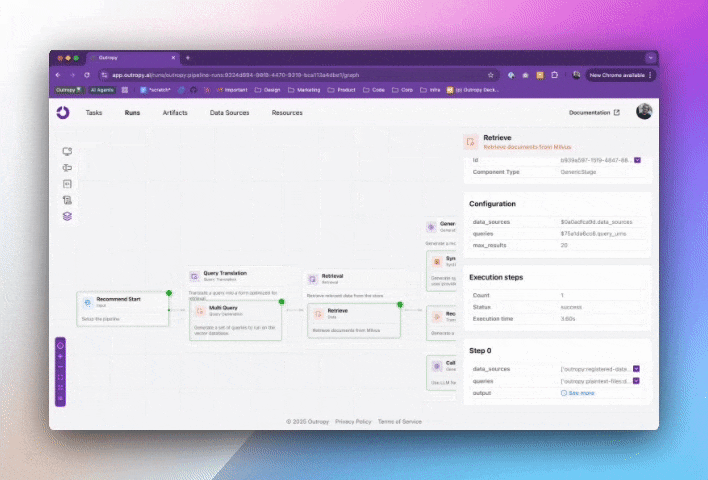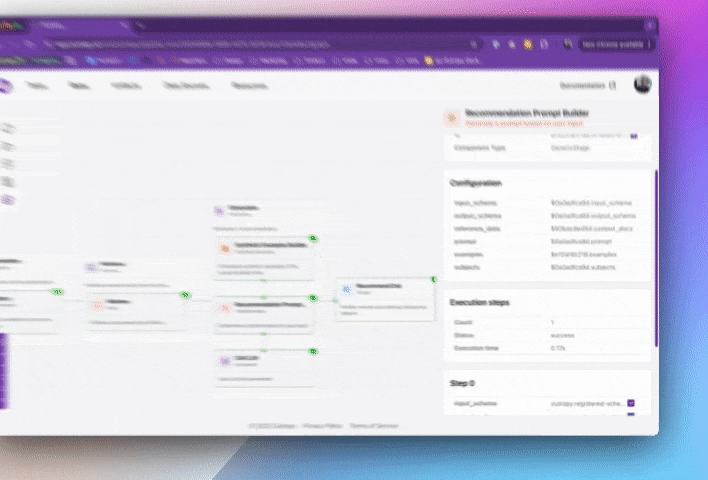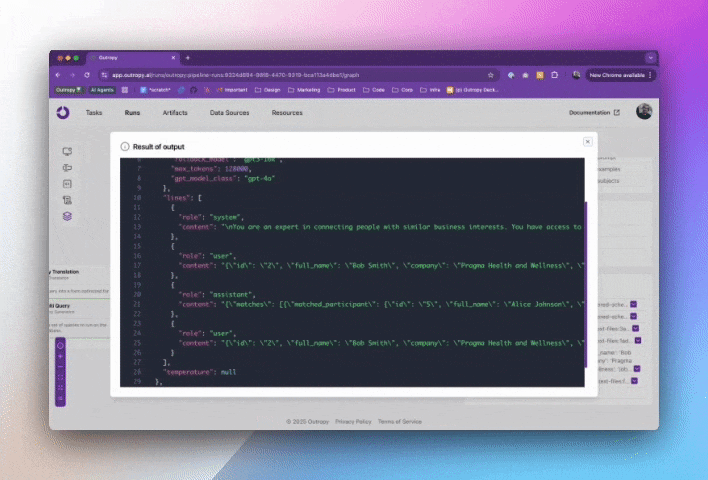
When you create a Task, Outropy automatically builds an AI inference pipeline for it. This isn’t just a wrapper around an LLM API - it’s a sophisticated pipeline that handles everything from data preparation to result generation. You can visualize and inspect these pipelines in the web UI:
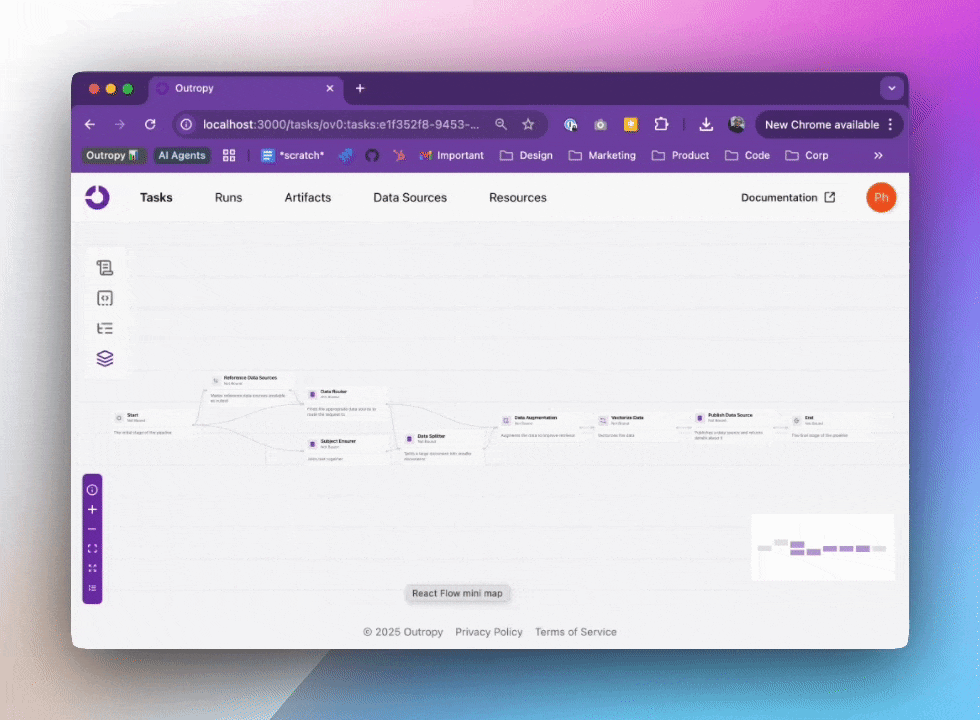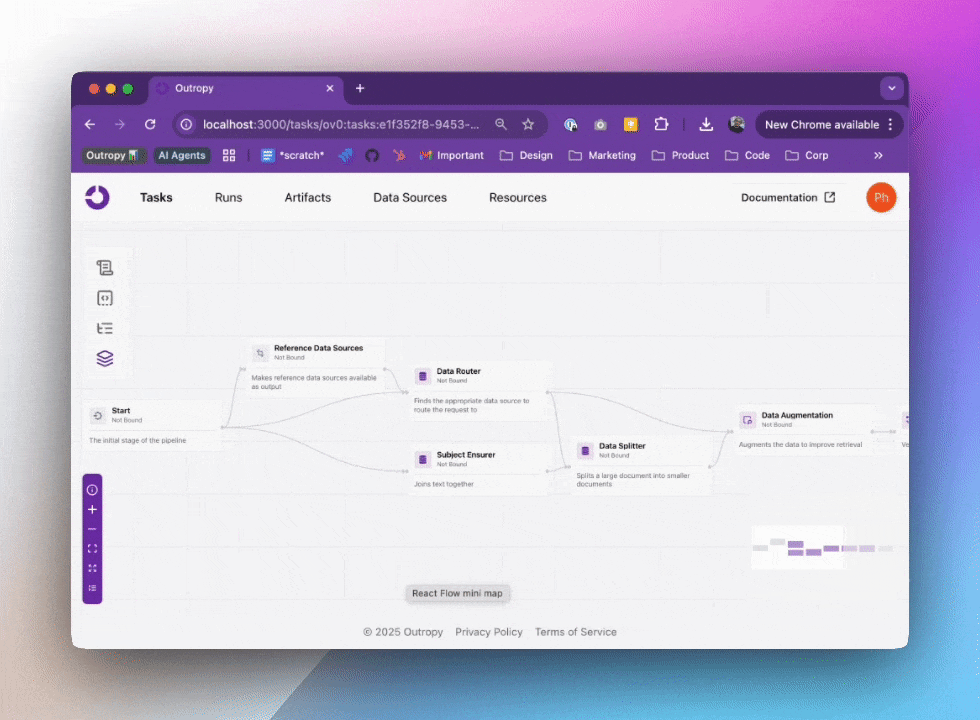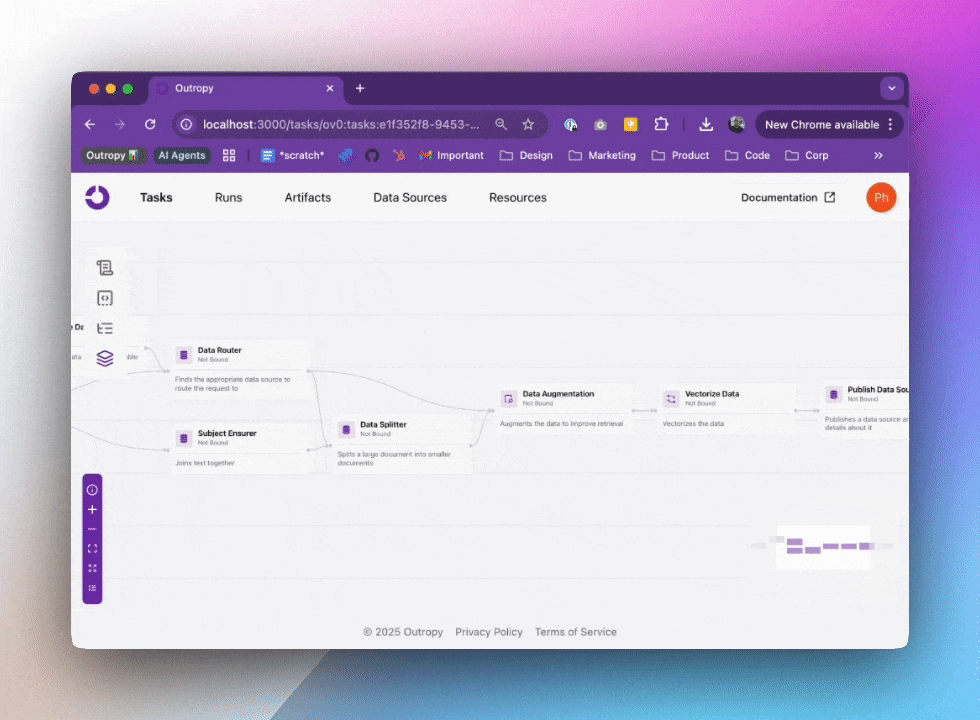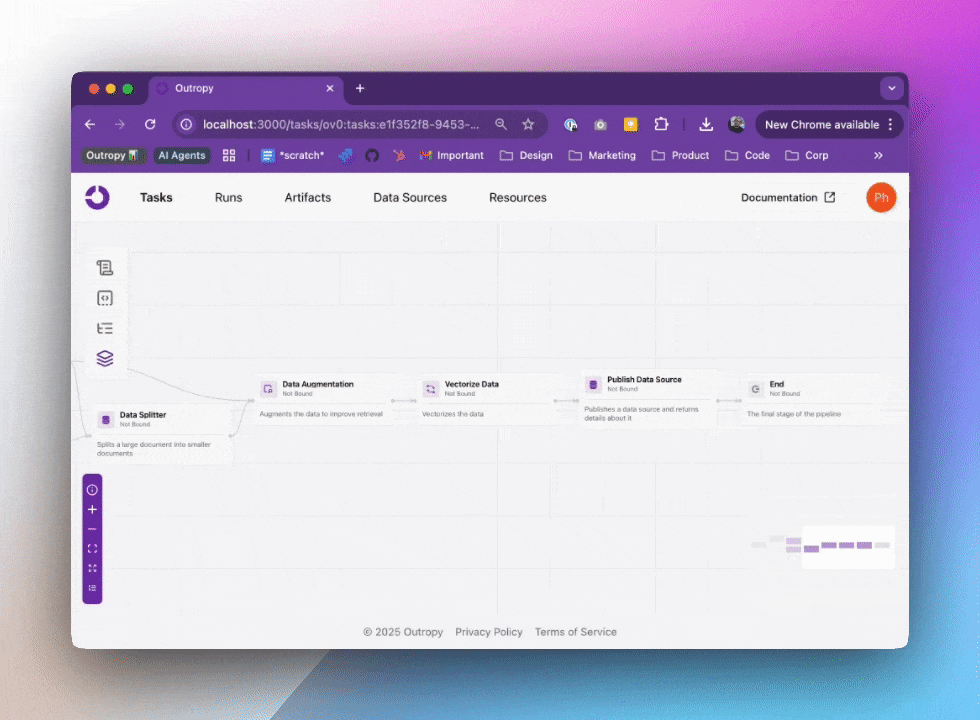
In this pipeline, Outropy automatically handles all the complexity of working with AI: selecting the right models, managing data flow, and optimizing performance. You don’t need to worry about details like caching, retries, or scaling as Outropy handles all of that for you.
What makes Tasks truly powerful is that this pipeline is just a blueprint. Outropy continuously learns from how your Task is used to optimize its performance and reliability. You can see these optimized pipelines in action:

While inspecting the pipeline is great for debugging and learning, you rarely need to think about it. In your code, using a Task is as simple as a method call:
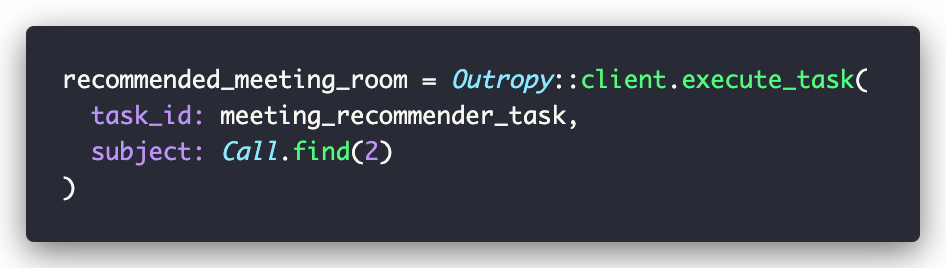
The Task handles all the AI complexity and returns exactly what you asked for - in this case, a MeetingRoom instance that fits right into your Rails application.
Tasks are permanent objects: once created, they get used many times over the lifetime of the system. We suggest that applications adopt the pattern of either finding an existing task or creating only when they start, and caching the task id somewhere to be used when invoking it.
Step 1) Meeting Categories
Now that we understand the basics of how to create and execute tasks in Outropy, let’s look at how to decompose a feature into smaller units.
As discussed before, one of the biggest improvements one can make in AI is to avoid thinking of it as a magic black box that can solve all problems without much direction. For Campsite’s specific case, we need to know what kind of meeting it is before we can give the model better instructions on how to summarize it.
First, let’s define our meeting categories. We’re using a simple MeetingCategory class here, but in a real application, this would typically be an ActiveRecord model:
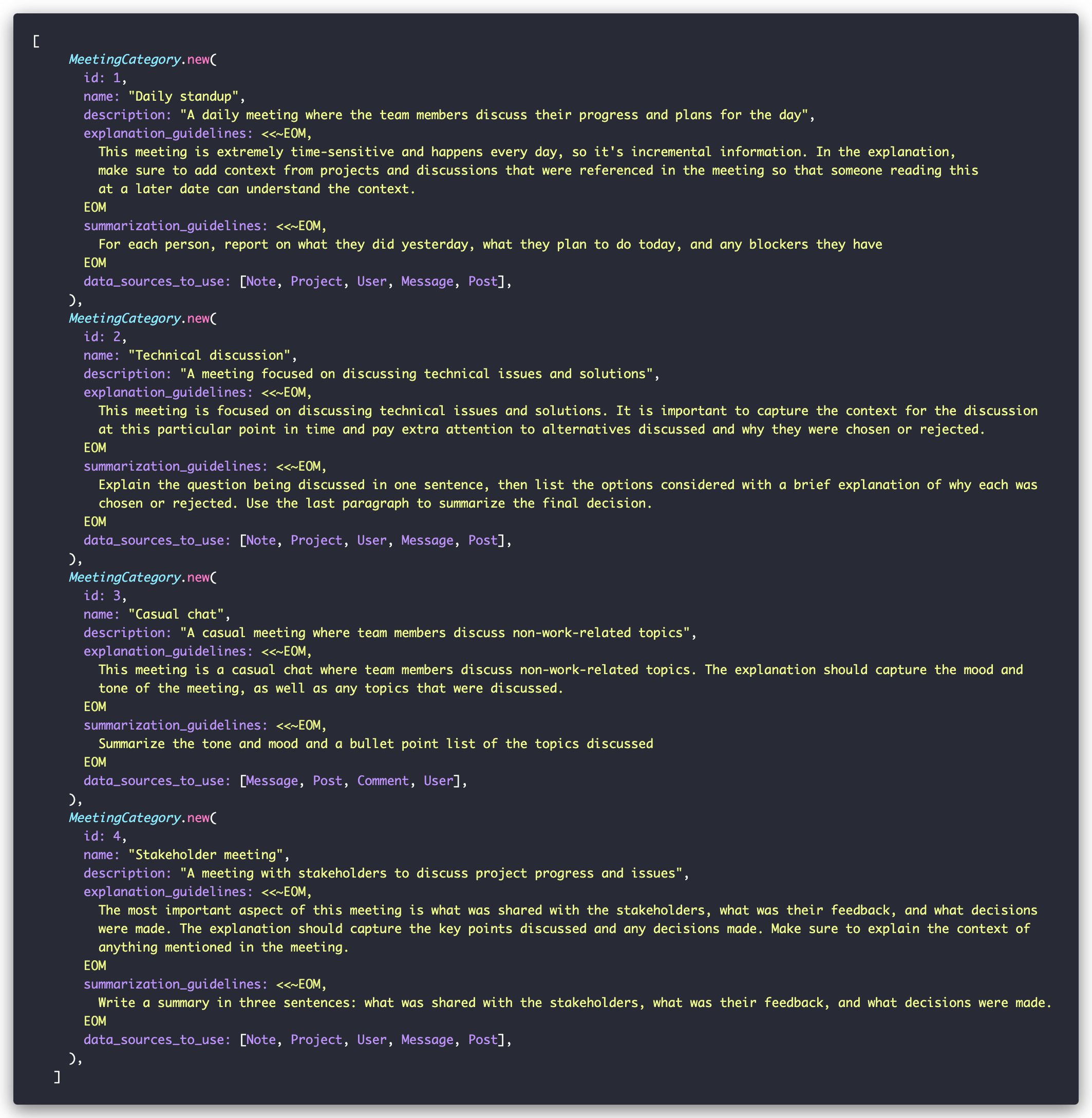
Each category includes specific guidelines for how its meetings should be handled. Depending on what you are building, you could let users define those based on their preferences or impose some if you want to nudge them towards best practices.
To make these categories available to Outropy, we wrap them in a MeetingCategorizer class that handles the integration:
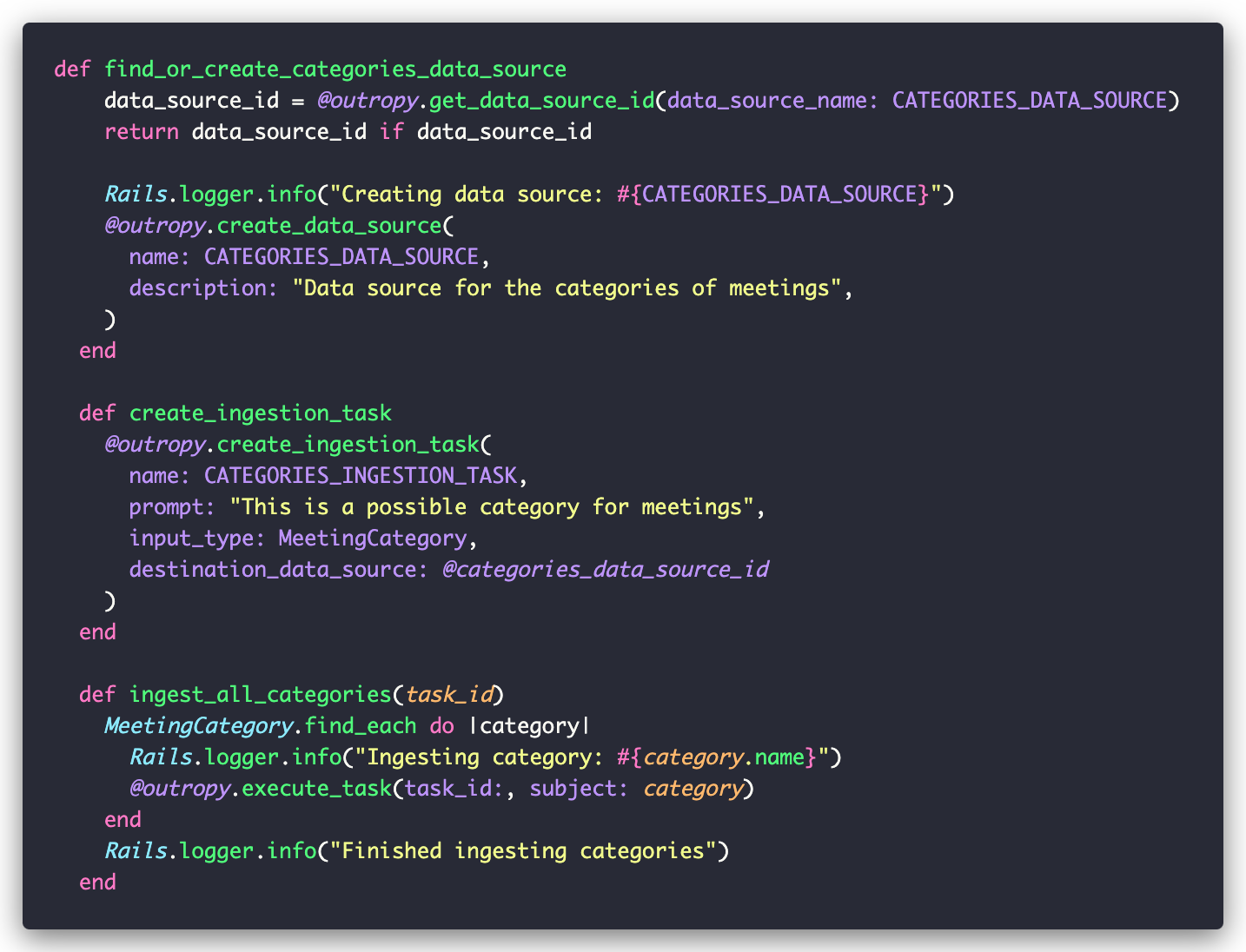
The categorizer creates a data source to store our categories and an ingestion task to populate it. Think of data sources as Outropy’s equivalent to database tables or search indexes, in that they’re where we store reference data that our Tasks can use.
Now that we have our categories stored, we can create a classification task to automatically categorize meetings.
Step 2) Classifying a Meeting
Now that we have our categories stored, we can create a classification task to automatically categorize meetings. Given a CallRecording , we want to determine which MeetingCategory from our catalog best describes it.
Let’s check out the two methods that handle this:
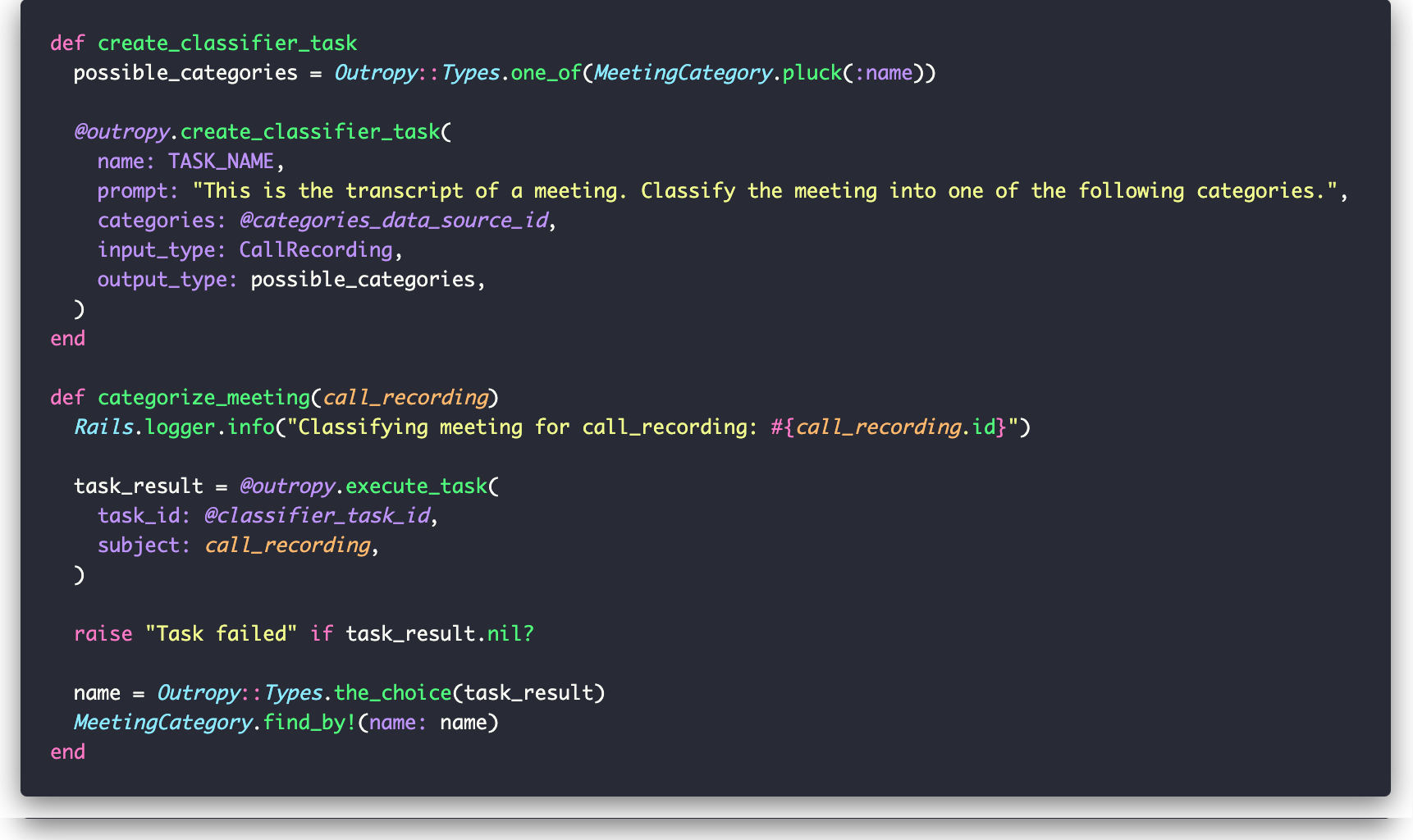
The structure of create_classifier_task should be familiar by now, with one small difference. Because we’re using Outropy’s convenience method for classify tasks, we list the possible categories as a specialized argument instead of just reference_data. This gives Outropy more information to optimize your task’s performance.
Once the task is created, we can use it to categorize meetings by passing in a CallRecording. . The task returns the category name, which we use to find the corresponding MeetingCategory. Here’s how it looks in the Rails console:
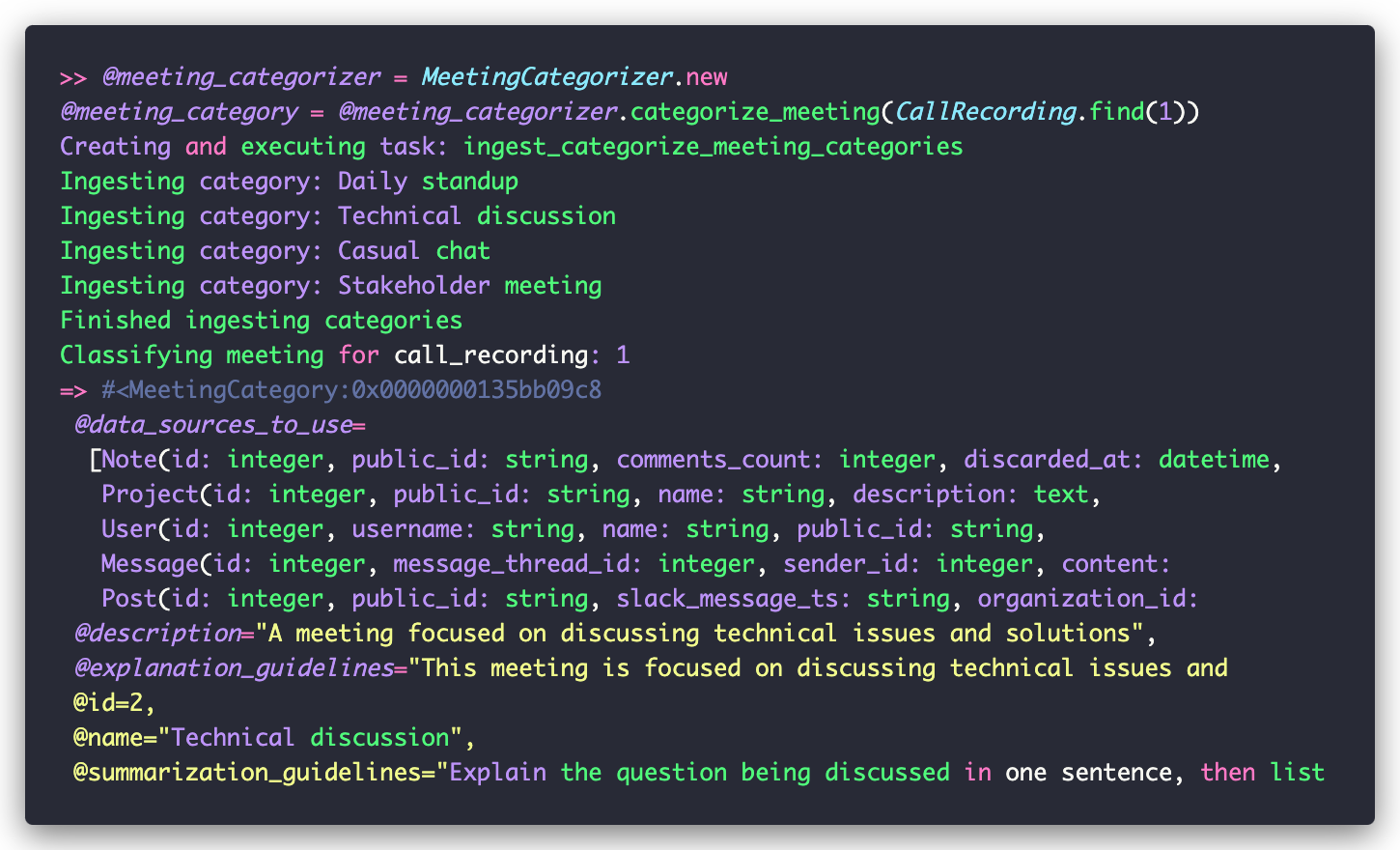
Step 3) Build an Explainer
When talking about preventing hallucinations, we introduced the idea that instead of building a summary from the raw content we should first generate a document that ‘explains’ the call. These documents contain not a summary but a detailed explanation of the content itself and its context—e.g. It could have a glossary, a list of people and other entities mentioned and what are their roles, etc. In our experience, asking the AI to summarize this document instead of the raw transcript is fundamental to avoid hallucinations and to have a summary that is more useful.
To make it easier follow, we wrote a MeetingExplainer with very similar structure to the categorizer we just saw. The overall pattern here should be familiar by now, so we won’t spend too much time there, but there are a few interesting things in how we create the task:
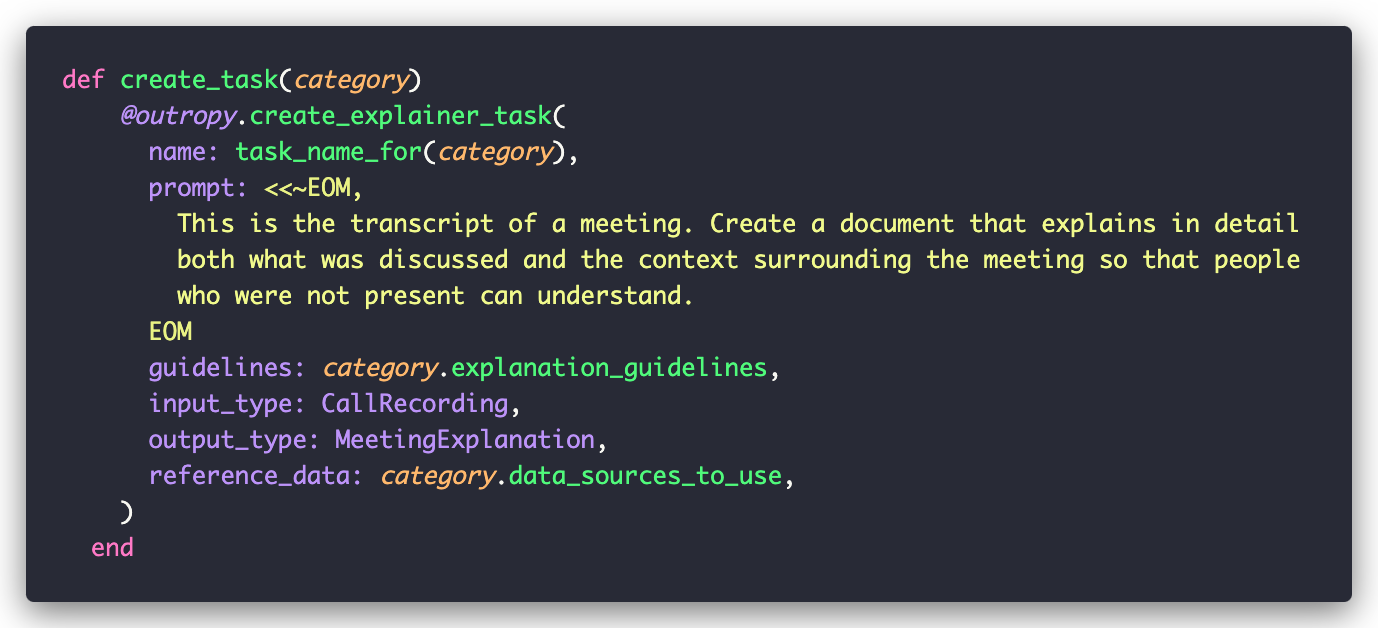
The first thing to notice is that we use the MeetingCategory object to find category-specific values. This is a common design pattern as people move from a simple demo to more useful AI-powered features.
The guidelines parameter is available to all tasks, and it can point to any data source or even just plain strings. It is used to inform Outropy that this particular set of guidelines should be applied when performing this task. This is super useful for things like coding styles, conventions, or even stage directions on the personality of an interactive agent. In this case, each category of meeting has their own guidelines on how to be summarized.
But the most interesting part here is the use of reference_data.We mentioned before that this field is used to let Outropy know which information should be available to this task, the Retrieval of RAG. In this case, the data sources available depend on the summary. For example, for a Technical discussion, we make available [Note, Project, User, Message, Post]. We also mentioned that these can be ActiveRecord models, but we haven’t seen how until now.
Step 4) Integrating ActiveRecord and AI
While you can use ingest tasks as shown before to ingest your models, it wouldn’t be a full Rails experience if we didn’t provide support for the framework’s powerful ActiveRecord object-relational mapping.
Your ActiveRecord models are automatically ingested by Outropy if you include the AutoIngest mixin. Let’s look at how it looks in the Call model:
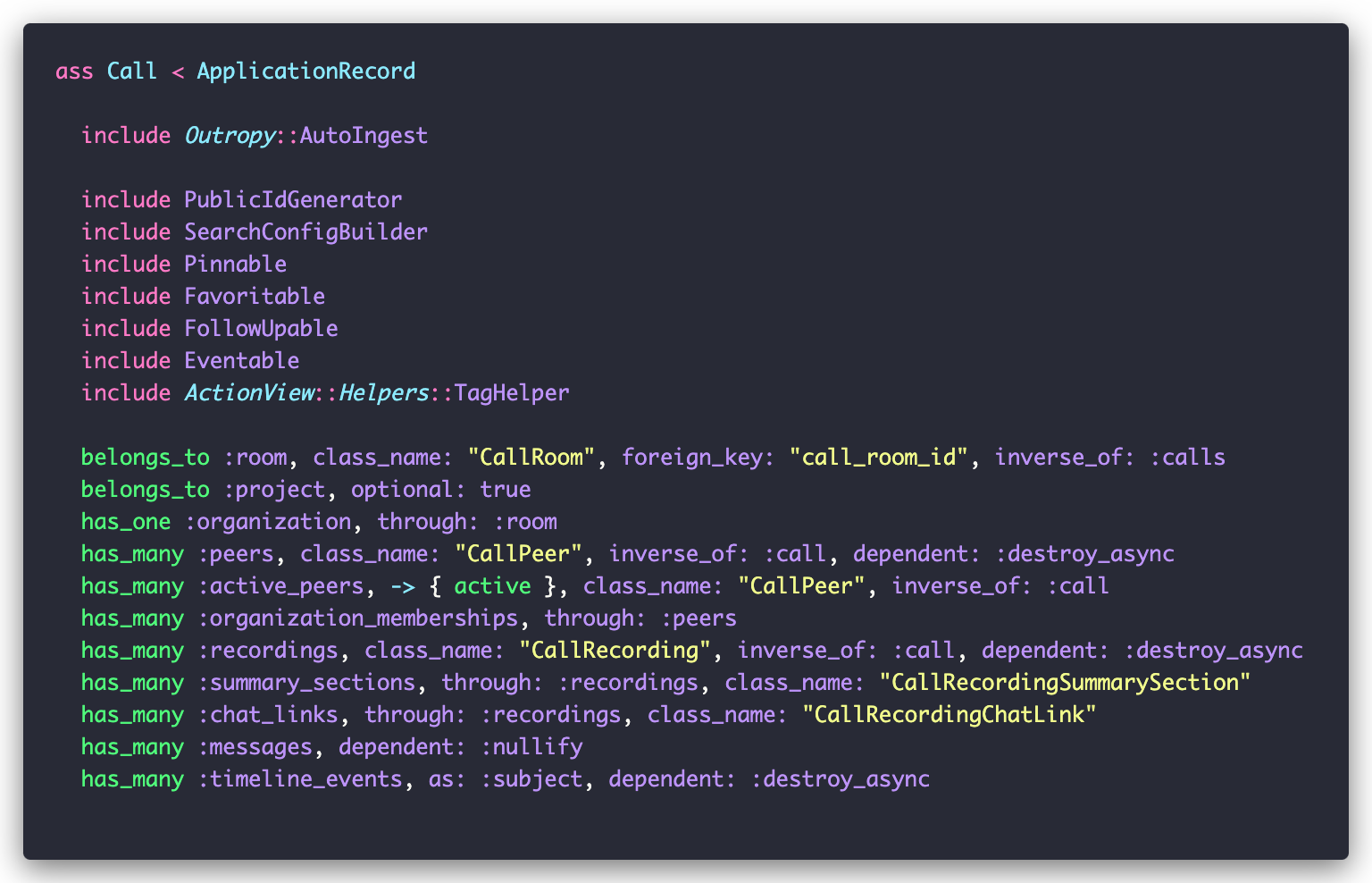
If you look at existing data sources in the Outropy web app, you’ll see that behind the scenes each model gets its own data source. Outropy hooks into the ActiveRecord lifecycle events to keep everything in sync using background jobs.

This means that your ActiveRecord models are always available to any task at Outropy, and you can conveniently just pass the class as reference_data. We are working on CQRS-style historical information; it should also be available soon.
Step 5) Generating the Explainer Documents
Now that we have access to the reference data we need to make sense of our meetings, it’s time to generate an explainer. Here is the output of Rails console—it’s a long one but I’ve uploaded the content to a gist for better readability.
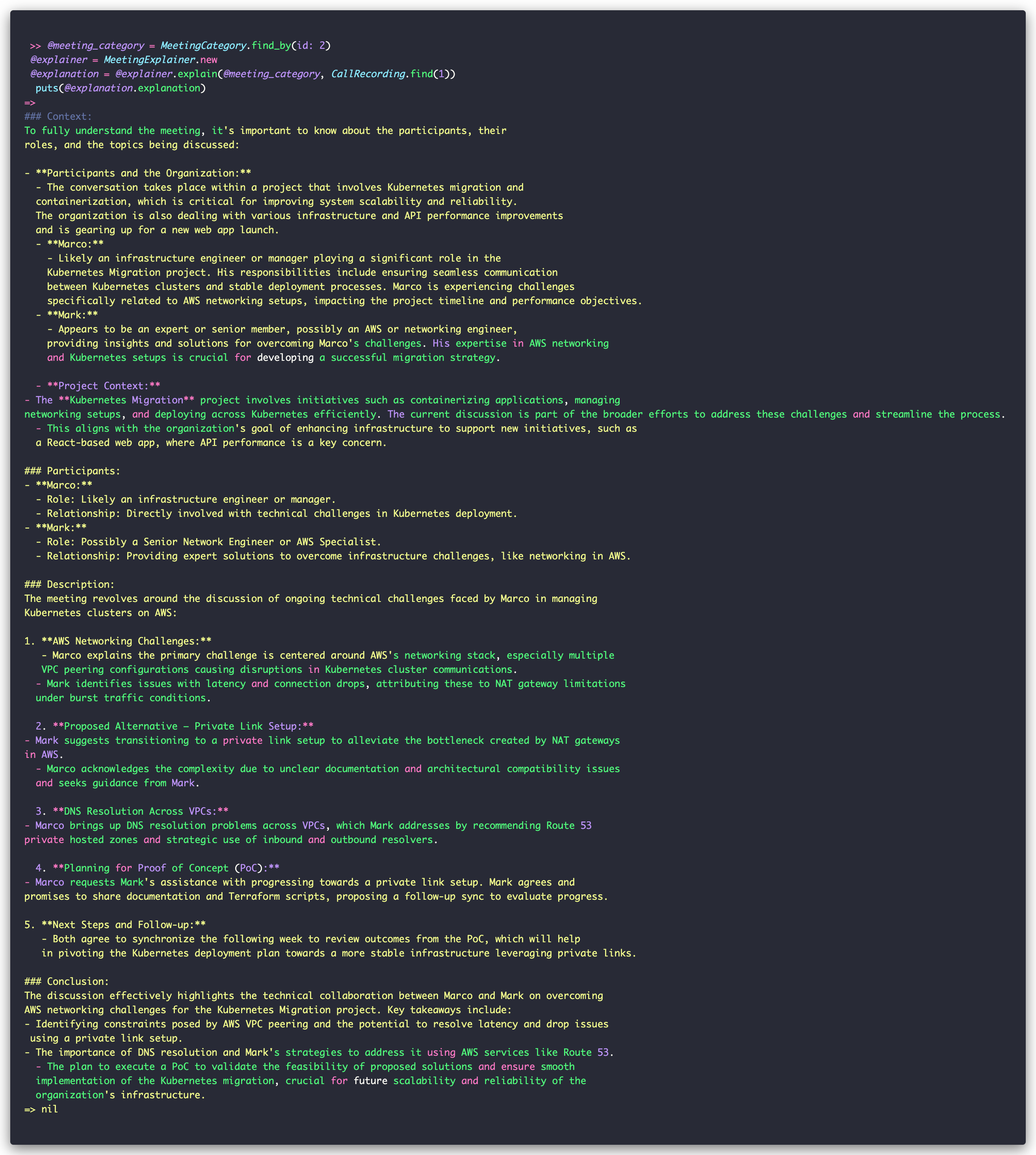
As you can see, the explainer made use of the reference data we gave it, including making references to other projects that were not explicitly mentioned in the call but might be impacted by the discussion.
Now that we have this comprehensive explanation, we can transform it into something more digestible. Let’s look at how to compile this rich context into a focused summary that highlights just the key points.
Step 6) Compiling the Explainer into a Summary
Our recommendation is that you store the explainer generated as the canonical data. If you want to perform more transformation on the data, for example if you want to perform sentiment analysis across all meetings, you should execute this task against the explainer, which will be faster, cheaper, and generate more consistent results.
And that’s what we are going to do in our case study. To make things compatible with Campsite’s original code, let’s create a class called MeetingSummary that contains the three sections defined in CallRecordingSummarySection:

You might notice here that these are not ActiveRecord models. While only ActiveRecord instances can be auto-ingested, you can use any type as input or output for Outropy. In this case, we are using ActiveModel with a little help from a mixin that comes with the Outropy SDK called RichAttributes. This mixin basically allows you to define description for your fields, which are also sent to Outropy as metadata that is used by our Reinforcement Learning engine optimizing your pipelines.
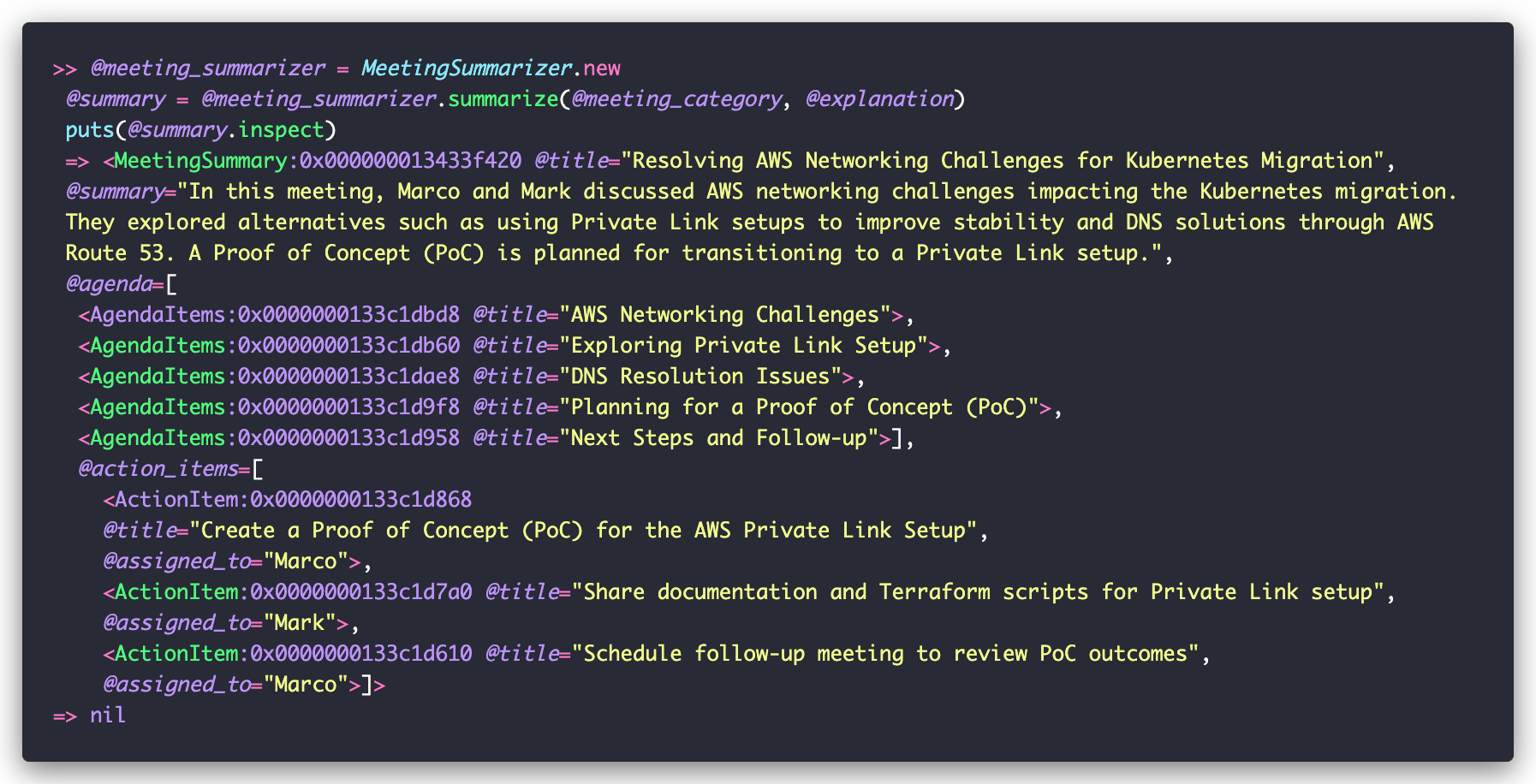
The creation of the summarization task should be familiar:

And as we execute it on Rails console, we get back a MeetingSummary that we can then use in our code normally:
Step 7) Putting it all together
One of the biggest advantages of the way we’ve been designing our code by splitting it into small, single-responsibility classes is that we can easily both write unit tests and, as we saw throughout this tutorial, manually test it on the Rails console. As much as Outropy automates away most of the trial and error in AI development, we are dealing with nondeterministic models and it is always good to be able to quickly try something out to make sure there’s nothing wrong.
But at some point we need to put all these components to work together. As our goal here has been to change the original Campsite code as little as possible, we are going to do this by creating our version of their background job:
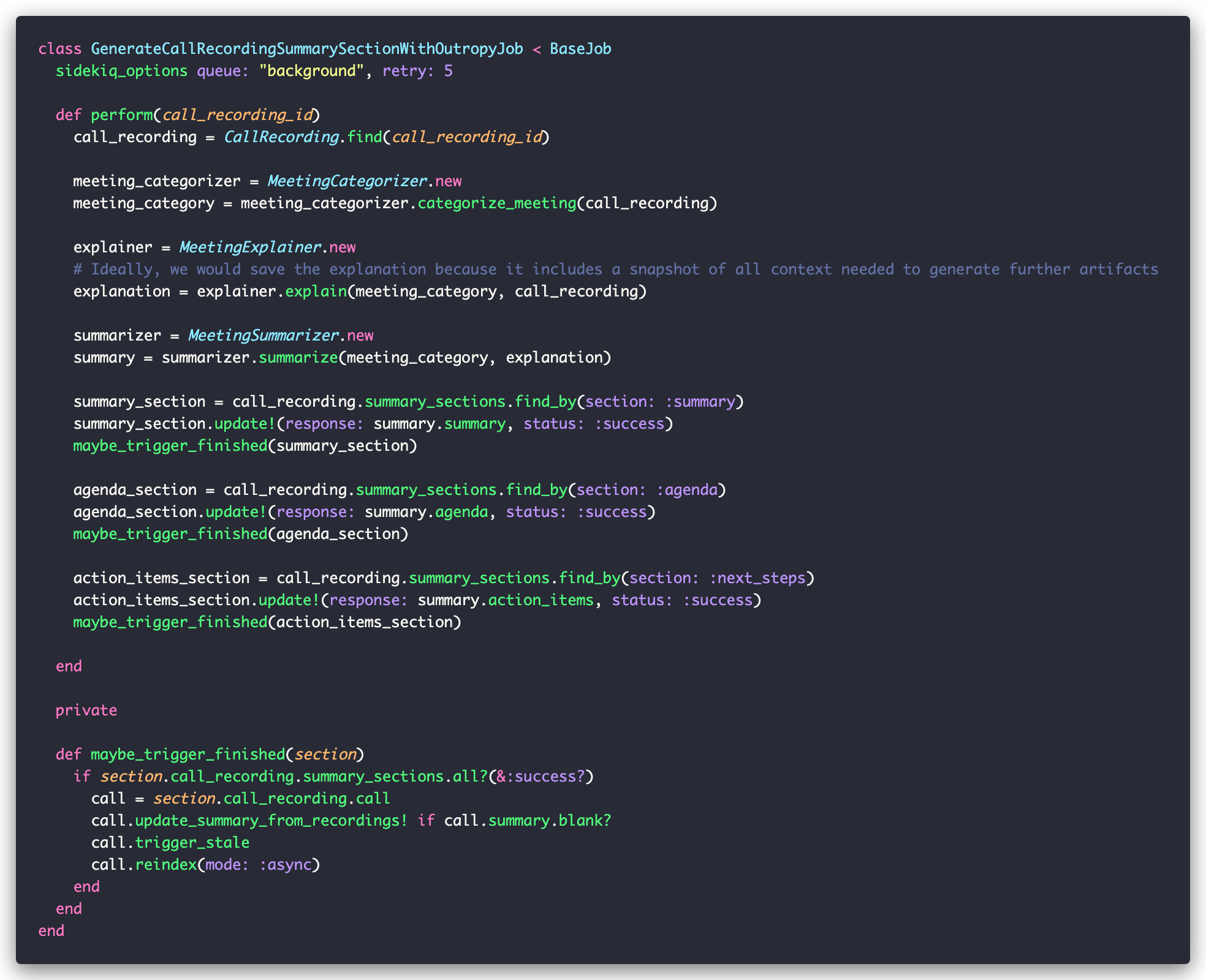
And there we have it, the new Outropy-powered summaries should be working on the web app!
Contrasting Both Summaries
Before we wrap up, let’s see how our context-aware approach compares to the original implementation:
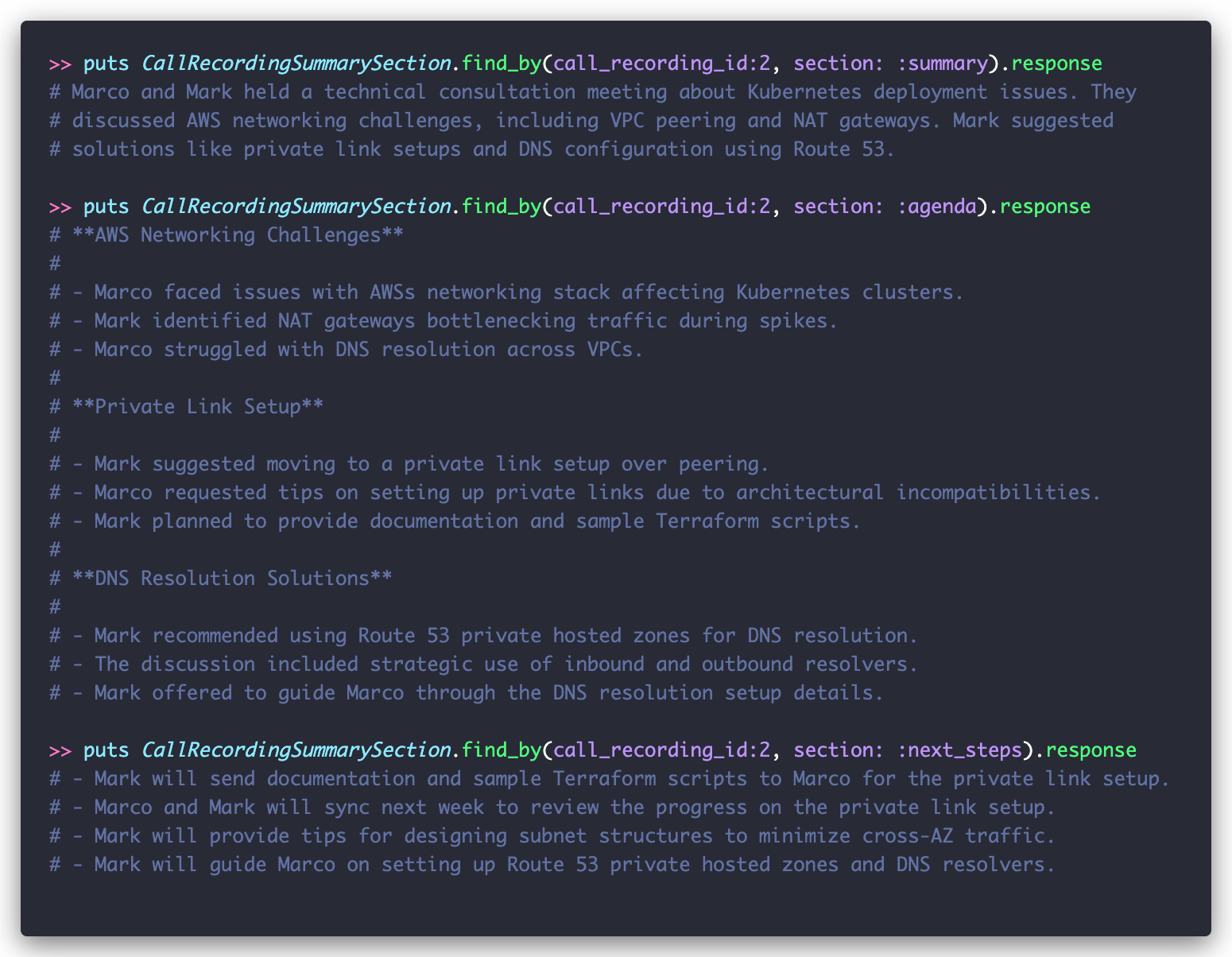
Looking at the original implementation, we can see three key issues:
- It’s merely condensing the transcript (which is only 14 lines!) rather than truly summarizing
- It’s packed with unnecessary conversational details
- Most critically, it lacks broader context about what project or initiative this relates to
Now compare this to the summary generated using our task-based approach:
We added the agenda items to be compatible with the existing code, but honestly it feels like it’s not needed. All you need to know is in the description, including that this meeting is related to the Kubernetes Migration project that wasn’t explicitly mentioned but Outropy inferred from Campsite’s Project ActiveRecord models.
As we iterate further, the next step here would be to not generate these generic summaries but instead call contextualize passing as a parameter the user that the summary is intended to. This will allow Outropy to add the right level of detail if the person is an engineer, a stakeholder, or maybe someone onboarding in this team and trying to get acquainted with what’s been going on.
Wrapping Up
We’ve seen how bringing AI features into Rails applications requires more than just calling LLM APIs. Through Campsite’s journey, we explored patterns that help manage complexity while maintaining Rails’ elegant simplicity:
- Breaking down AI features into focused, composable tasks
- Using context effectively to prevent hallucinations
- Integrating AI naturally with your domain models
- Making AI operations feel native to Rails
These patterns work regardless of your AI stack, but Outropy makes them particularly easy to implement. Our Rails integration is in beta, alongside native SDKs for TypeScript, Python, Java, and C#. For other languages, our REST API provides the same capabilities.
Ready to build better AI features in your Rails app? Sign up for the beta here or reach out to me directly at p@outropy.ai