The Tokenomics of AI
- Artificial Intelligence
- Cost Management
- Strategy

Phil Calçado
It’s okay for that amazing AI demo you built to burn a few dollars every time it runs, but as your code gets closer to production, you need to start worrying about costs.
Building GenAI applications usually means RAG (Retrieval Augmented Generation). In its simplest form, it is a data pipeline that finds relevant content sent with the user prompt so that the LLM has context specific to your domain, your proprietary data that wasn’t part of its training.
In practice, this simple idea grows in complexity with the addition of modules that improve the quality of the results and add layers of fact-checking to prevent hallucinations. LangChain has a great illustration of the many modules that one can add to the pipeline:
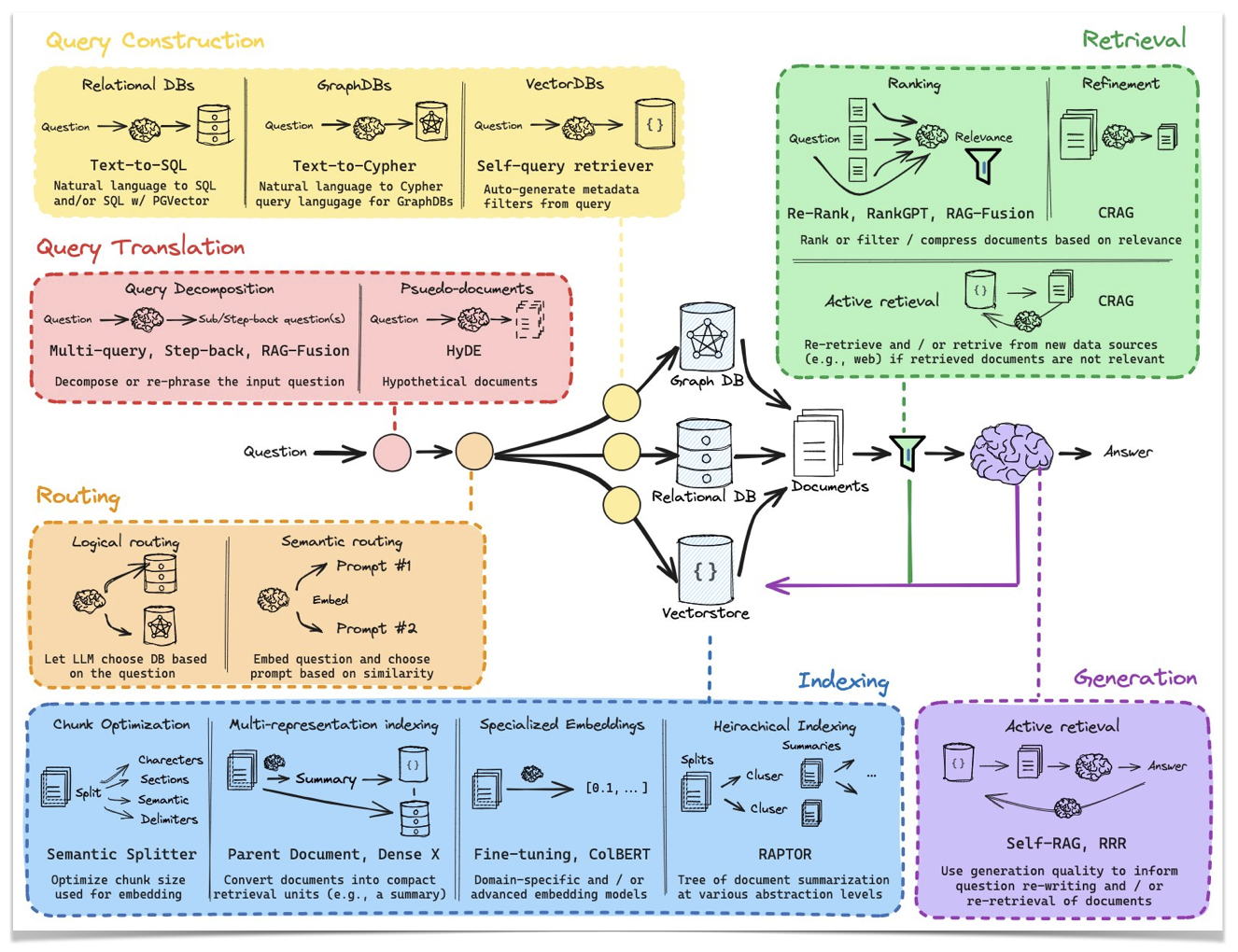
The complexity of what has now become a heavily distributed system is a big problem, but it is not the only one. Even if you have AI experts on staff to build the most optimized pipelines, a production-ready RAG will send and receive tokens to the LLM many times before it actually sends the user prompt.
This extra cost often comes as a surprise, usually close to launch. Once faced with the bill, engineers start removing components from the pipeline, eventually decreasing the quality and usefulness of the feature.
Cost optimization and management are among the main reasons users adopt Outropy as their AI application platform. A recent conversation with a publishing company using Outropy to develop AI features for their platform made me think of how similar this is to what we’ve experienced in previous technological waves…
(btw, apologies to my crypto friends for co-opting their terms, but it was just too good)
A Serverless Tale
In 2017, WeWork acquired Meetup. The sleepy staple of the early 2000s New York startup suddenly saw itself asked to move at the hypergrowth speed of Adam Neumann’s dreams. As part of this transition, WeWork brought people with experience in Internet-scale startups to bring the business and its almost 20-year-old codebase to match the expectations of hypergrowth. I was part of this batch of new hires and headed Meetup’s platform and infrastructure teams. I discussed some of the challenges in this transition in a talk I gave at QCon a few years ago,
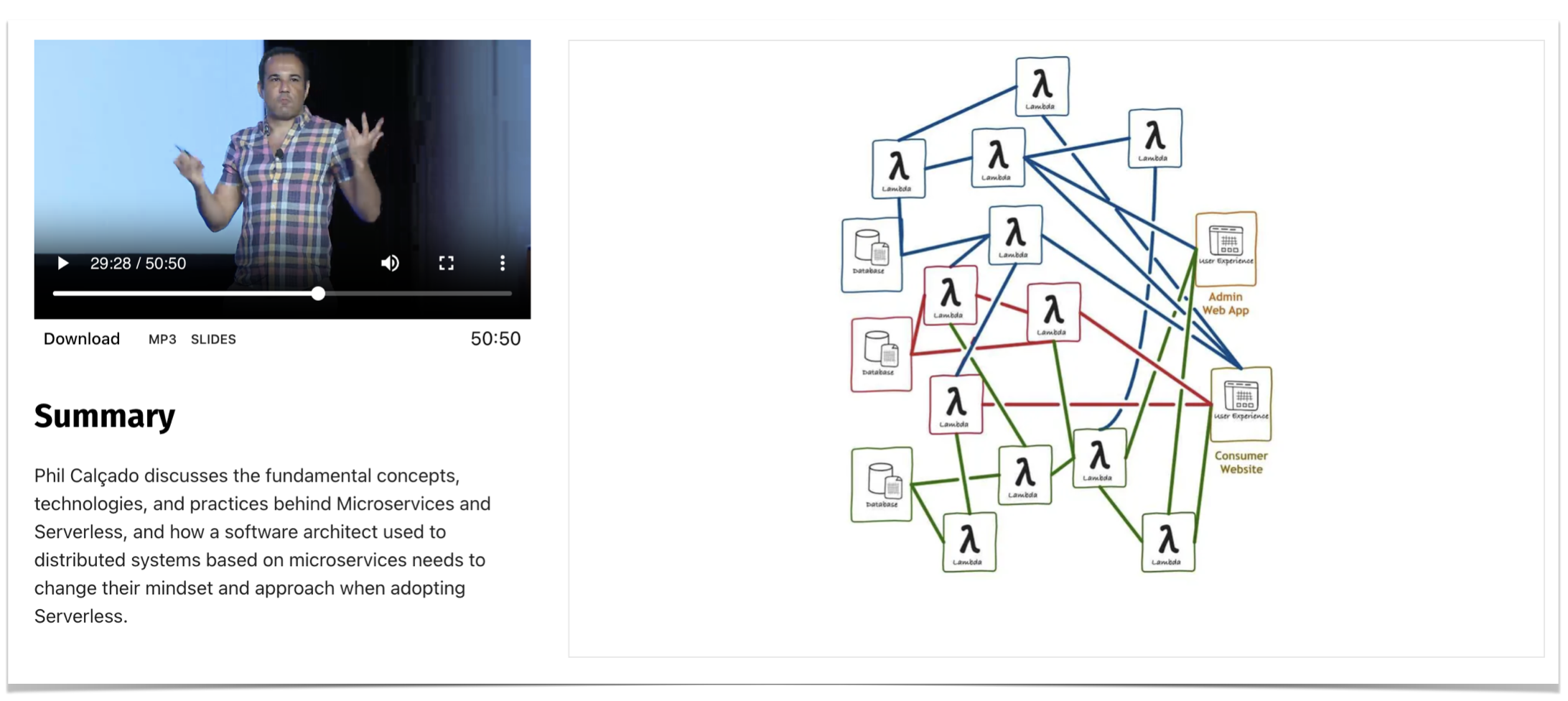
To allow product engineers to move faster, one of my teams was working on a project to make it more productive to reuse features from Meetup’s legacy codebase. The work was similar to what I had previously done successfully for SoundCloud, so I was confident in our ability to deliver.
The new serverless architecture allowed product engineering teams to build and run features using Typescript in AWS Lambda. This was great for new features, but all of Meetup’s legacy and infrastructure code was in Java and Scala. These languages run on the JVM, a runtime poorly suited for platforms such as AWS Lambda. The solution we found to run those components in our serverless architecture was to use the then-brand-new AWS Fargate.
The issue with this plan was that Fargate’s pricing was very high. It was definitely too high for my operations budget. Oversimplifying the situation a little, this left us with two options:
1. Port the must-have infrastructure code from the JVM code to TypeScript so it can run as Lambda
2. Port the application code from TypeScript to Java/Scala and use the old infrastructure.
And I always ask my engineering teams to consider a third option—it’s codified in my RFC process, even—so we had a third option:
3. Do nothing: deliver the system as is, eat up the costs, and find opportunities to optimize later.
This project aimed to accelerate product engineering teams, so (2) was hardly an option. Option (3) would allow us to deliver value immediately, but we were afraid that other priorities would prevent the team from iterating on finding cost-effective solutions anytime soon, and our AWS bill would grow by a few orders of magnitude overnight.
Option (1) was not great because it would delay the value to our customers, but we were confident that the amount of code that had to be ported wasn’t that big, and we could do it in a few weeks.
We went with option (1), and as you might expect, a few weeks became a month and then a few months. We eventually delivered the new architecture, but by then, our product teams had already started using alternative approaches to deliver their backlogs. Now, it was our job to port these back to the new architecture.
About one month after we delivered the architecture, AWS announced a 50% reduction in Fargate prices and was working on making further reductions soon. This price drop made the whole project redundant; running our JVM systems would have comfortably fit into the budget.
So, in hindsight, the correct choice would have been to do nothing.
Token Shaving is the new Yak Shaving
Anyone who has lived through the cloud revolution of the late 2000s has many stories like the one above. Betting on cloud providers to decrease their prices is almost always a win.
You might expect this is where I tell you not to worry; just keep using your favorite model, and prices will fall into your budget. Well, yes and no.
I am absolutely sure that prices will continue to go down—I am writing this one week after OpenAI reduced their prices by 60%! But counting on price reductions is a long-term strategy_,_ and it has its limitations.
It is a long-term strategy because you will definitely benefit from the lower costs over time, but in today’s funding climate, it is very unlikely that your organization has the luxury of not worrying about costs and margins today.
It has limitations because it is unlikely that the current AI generation will ever be truly cheap. Inference in LLMs still depends on scarce, slow, and expensive resources, and the race to the bottom that we see now as AI companies try to undercut each other will hit a, well, bottom.
What I usually recommend to people building AI applications is:
Understand your actual pipeline
Something we learned from microservices is that what is documented is not what is in production. With microservices, we had distributed tracing tools like Zipkin; with AI systems, there are many tools, such as LangWatch, that can help.
Correlate costs with features
There are many tools that monitor LLM costs, but most of them group costs per API key used, making it impossible to understand which call was made to support which product feature. If you are building your RAG pipelines with a framework that supports traces, you can write code that keeps track of which features originate from which traces and tries to reconcile them.
Enforce a maximum budget
More sophisticated pipelines will sometimes have bugs that cause a large amount of tokens to be sent to LLMs erroneously. Even if your own code is perfect, there are many cases of LLMs getting into weird loops that return an excessive number of tokens. As much as monitoring and alerting are essential to detect those, you should set an upper limit on the maximum number of tokens a pipeline can use. When the limit is reached, the pipeline should abort the processing and report the error to admins. This can save you from a very high bill created by mistake.
Build a pipeline router for different features and users
Not all features are the same, and not all users are the same. Firstly, different features will fundamentally require different pipelines. For example, retrieving context for a Q&A bot is different from a tool that generates code to parse an arbitrary data structure. But there’s also a question about quality of service. You should vary the quality of results depending on where a feature is used (say, a quick summary vs an in-depth analysis of some content), the type of user (free users vs. personal plans vs. enterprise plans), or other dimensions. This helps avoid wasting tokens producing throwaway content and helps build healthier profit margins.
Cache and cache and cache
Caching LLMs is always challenging because of the nondeterministic nature of its inputs and outputs—ETag-like strategies won’t work here. Effective caching in LLM-based applications will not rely on raw text but will often use something similar to Abstract syntax trees (AST) such as Abstract Meaning Representation - Wikipedia and other graphs.
Let the Platform Shave your Tokens
These are just a few examples of the many strategies you can use to keep your costs under control. We focused on cost here, but when building AI applications with LLMs, it is essential to note that cost correlates with latency, so cheaper applications tend to perform better.
Unfortunately, most companies lack the AI experts on their staff to design and implement these steps. Even those with the luxury of a dedicated AI team can’t support all the product teams that need help building AI features.
This is why we are building Outropy, a Platform-as-a-Service that performs all these optimizations and more and offers a simple REST or GraphQL API that your product engineers can use without investing six months in research.
I would love to hear about what you are doing with AI and how we could help. Our calendar is here, my email is phil at outropy, and we’d love to grab a coffee if you are in NYC.